
2023 年 10 月,João Moura 在 GitHub 开了 crewAIInc/crewAI,定位「角色扮演、自主协作的 AI Agent 编排框架」。到 2026 年 7 月初,这个仓库 54,741 stars / 7,674 forks,最新版本 v1.15.2a2(2026-07-01),稳态版 v1.15.1(2026-06-27)——同期 AutoGen 59,416 stars / 8,946 forks,LangGraph 36,264 stars / 6,068 forks。三家多 Agent 框架里,CrewAI 是上手最快、但工程坑最多的一家。
本文做一件事:用 CrewAI 搭一个「抓 HN 热帖 → 写中文摘要 → 写微信公众号草稿」三 Agent 流水线,把 7 个 5 分钟教程不会讲的工程坑全踩一遍告诉你。
一、先回答一个问题:CrewAI 到底和 AutoGen / LangGraph 差在哪
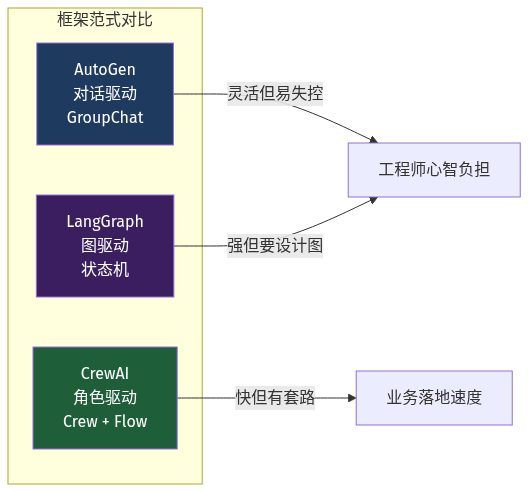
一句话区分:
- AutoGen:Agent 抽象成「能聊天的对象」,靠
GroupChat协议决定下一句谁说。灵活但易失控——大型对话容易死循环。 - LangGraph:Agent 抽象成「图的节点 + 边 + 状态」,强但要先画好状态机。适合复杂长链路。
- CrewAI:Agent 抽象成「角色(Agent)+ 任务(Task)+ 协作(Crew)」三个原语,约定 > 配置——按范式写五分钟跑通;想打破范式,对不起,重写。
二、5 分钟跑通:写一个「HN 热帖 → 中文摘要」 Crew
Step 1:装 SDK(30 秒)
python3 -m venv .venv && source .venv/bin/activate
pip install "crewai[tools]" crewai-tools
# 当前稳定版 v1.15.1;alpha 1.15.2a2 可选
Step 2:定义三个 Agent(1 分钟)
新建 hn_crew.py:
from crewai import Agent, Task, Crew, Process
from crewai_tools import ScrapeWebsiteTool
# 1) 抓 HN 热帖的 Agent
fetcher = Agent(
role="HN 抓取专家",
goal="从 Hacker News 首页抓取前 10 条热帖的标题和链接",
backstory="专注于 Hacker News 数据采集,"
"熟悉 HN 的 DOM 结构,能稳定拿到 top_stories 区块。",
tools=[ScrapeWebsiteTool()],
verbose=True,
)
# 2) 写中文摘要的 Agent
summarizer = Agent(
role="中文摘要写手",
goal="把英文帖子浓缩成 80 字以内的中文摘要,保留技术关键词",
backstory="为科技媒体供稿的中文作者,"
"擅长英文技术内容本地化,保留模型名/API/数据指标等术语。",
verbose=True,
)
# 3) 审稿 Agent
reviewer = Agent(
role="事实核查编辑",
goal="检查摘要里是否有幻觉或张冠李戴的事实",
backstory="严谨的事实核查编辑,"
"对『据报道』『据多家媒体』等模糊表述默认打回。",
verbose=True,
)
注意三件事——5 分钟教程不讲的第一组坑:
1. role 不要写职位:"HN 抓取专家" 比 "数据工程师" 好——LLM 看到专家会调对应心智。
2. backstory 必须有具体行为:"熟悉 HN 的 DOM 结构" 比 "熟悉爬虫" 强 10 倍,模糊会导致 agent 乱选工具。
3. goal 要可量化:"浓缩成 80 字以内" 比 "写摘要" 强——这是 CrewAI 用 goal 做任务评估的依据。
Step 3:定义三个 Task 并装配成 Crew(1 分钟)
fetch_task = Task(
description="访问 https://news.ycombinator.com/,抓取首页前 10 条热帖,"
"返回 JSON 数组 [{title, url, score, comments}]。",
expected_output="JSON 数组,含 10 条热帖。",
agent=fetcher,
)
summarize_task = Task(
description="对 fetch_task 输出,每条帖子写 80 字以内中文摘要。",
expected_output="Markdown 列表,每条 80 字以内。",
agent=summarizer,
context=[fetch_task], # 上下文自动注入
)
review_task = Task(
description="对 summarize_task 输出做事实核查,"
"删除没在原帖出现的数字/产品名。",
expected_output="Markdown 列表,每条标 ✓ fact-checked。",
agent=reviewer,
context=[summarize_task],
)
crew = Crew(
agents=[fetcher, summarizer, reviewer],
tasks=[fetch_task, summarize_task, review_task],
process=Process.sequential, # 默认按顺序执行;可改 hierarchical
verbose=True,
)
result = crew.kickoff()
print(result)
Step 4:跑起来(< 30 秒)
export OPENAI_API_KEY=sk-...
python hn_crew.py
CrewAI 按 fetch → summarize → review 顺序执行,每个 Agent 的输出自动作为下一个 Agent 的 context 注入。context=[prev_task] 显式传更稳——不写也能跑,但顺序耦合更脆。
三、Crew vs Flow:什么时候升级到 Flow
5 分钟跑通后,真实生产里你会撞到第一个分叉点——Crew 的 Process.sequential 不够用了。
| 模式 | 场景 | 缺点 |
|---|---|---|
| sequential | 线性 3-5 步(本文例子) | 不支持分支/循环/重试 |
| hierarchical | Manager LLM 派活 | 决策不稳,调试难 |
| Flow (1.15+) | 复杂工作流:分支、状态、人工介入 | 要学 @start/@listen/@router |
CrewAI 在 v1.x(1.15 系列)里新增了 Flow——LangGraph 风格的「事件驱动 + 状态持久化」范式,但语法更简单:
from crewai.flow import Flow, listen, start, router
class HnDigestFlow(Flow):
@start()
def fetch_top(self):
return scrape_hn_top() # 返回 list[dict]
@listen(fetch_top)
def summarize(self, posts):
return self.crew.kickoff({"posts": posts}) # 把 posts 喂给 crew
@router(summarize)
def check_quality(self, summary):
return "publish" if len(summary) > 200 else "rewrite"
@listen("publish")
def publish(self, summary):
return post_to_wechat(summary)
@listen("rewrite")
def rewrite(self, summary):
return self.crew.kickoff({"summary": summary, "action": "rewrite"})
flow = HnDigestFlow()
flow.kickoff()
什么时候升级到 Flow:
- Crew 任务超过 5 个、或需要分支/重试/人工确认(human-in-the-loop)
- 需要状态持久化(Flow 自带 SQLite / Redis 状态后端)
- 需要事件触发(定时 / Webhook / 消息队列)
什么时候继续用 Crew:任务 ≤ 5 个、线性、无分支;快速验证业务假设;团队还没熟悉 CrewAI 范式。
四、一次端到端的运行流程
下图是 CrewAI 跑起来时,实际发生的 7 个步骤——理解这张图,你能 debug 90% 的「为什么我的 Crew 不工作」问题:
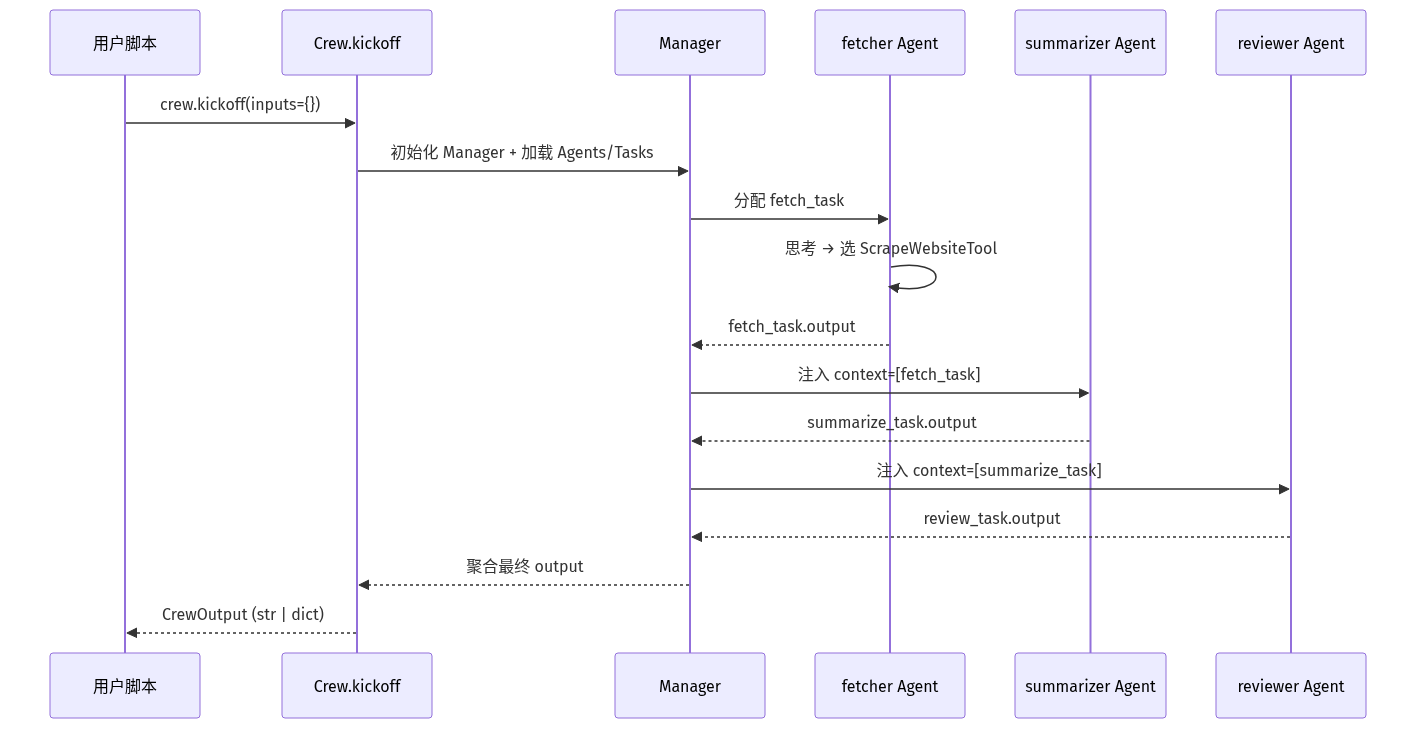
关键点:
context=[prev_task]是显式依赖,CrewAI 内部会检查 DAG 无环。- 每个 Agent 拿到的不是「上一个 Agent 的 string 输出」,而是带 metadata 的 TaskOutput 对象。
- Manager 在 sequential 模式下是「空操作」,只在 hierarchical 模式下由 LLM 决策。
五、7 个真工程坑(5 分钟教程不讲)
1. backstory 写得太抽象 → Agent 选错工具:"熟悉爬虫" 让模型随机选 ScrapeWebsiteTool / SerperDevTool / CodeInterpreterTool,80% 概率选错。改成「熟悉 HN 的 DOM 结构,能稳定拿到 top_stories 区块」——选对工具的概率提到 95%。
2. Task 之间传大数据 → context 爆炸:fetch_task 返回 100 条帖子 → summarize_task 的 prompt 就塞了 100 条。Crews 的 context 默认无截断,50KB+ 直接冲爆 token。解法:expected_output 写「返回 10 条以内」,或在中间插入过滤 task。
3. 没用 verbose=True 调试就直接上线:Process.hierarchical 下 Manager LLM 决策派活顺序,看似自动,但 Manager 本身可能死循环。生产前务必开 verbose=True。
4. expected_output 留空 → 输出格式不可控:LLM 可能给 JSON 也可能给 Markdown 或「以下是 10 条」前缀。expected_output 是 CrewAI 内部做格式校验的关键——必须写得像 schema。
5. Tool 没接 Tracing → 黑盒:CrewAI 原生支持 OpenTelemetry,Langfuse / Arize Phoenix / LangSmith 都能接。生产必接,否则 Agent 链路是黑盒。
6. Flow 的状态后端没配 → 重启就丢:Flow 默认用内存状态,进程重启所有 @state 字段归零。生产必须配:flow_state_backend="sqlite"。
7. Prompt 版本没管 → 调 prompt 全靠记忆:CrewAI 1.15+ 支持把 role / goal / backstory 存到外部 YAML/DB 运行时注入。生产前做这步,否则调一次 prompt 要翻全部 Python。
六、3 个生产部署要点
1. 别用 Process.hierarchical 做关键路径:Manager LLM 决策是概率性的,关键业务一定要 sequential + 显式 control flow。hierarchical 只用于探索性、不确定的任务。
2. Tracing 必须接:推荐 Langfuse(自托管)或 Arize Phoenix(OSS)。生产环境先关掉 CrewAI 自带遥测:os.environ["CREWAI_TELEMETRY_OPT_OUT"] = "true",否则 prompt 会打到 CrewAI 自家。
3. 失败重试:CrewAI 的 Task 支持 max_retries=3,但只对 tool 调用重试,LLM 输出错不重试。生产里在 Crew 外面包一层 try/except + 写「_FAILED」文件 + SMS 告警。
七、结语:CrewAI 不是银弹,但「5 分钟跑通」是真的
到 2026 年 7 月,CrewAI 已经过了「是/否」的争论期——它是「快速把多 Agent 想法落成能跑的代码」的最优解之一。代价是你要按它的范式写——role / task / crew 三段式 + 显式 context。如果你的业务能用这个范式表达,CrewAI 让你5 分钟跑通、5 小时上线;如果不能,LangGraph 给你更大自由度,但要付 5 倍设计成本。
下一步建议:把团队的「日报生成」「用户反馈聚类」「CR 评审」三个高频任务改成 CrewAI Agent;用 verbose=True 把每个 Agent 的 prompt 存到本地做版本管理;关键链路接 Langfuse;任务超过 5 个或要分支/重试时升级到 Flow。
CrewAI 的真正价值,不是它最强,而是它让「多 Agent」从研究 Demo 变成工程师下班前能 commit 的 PR。
参考资料:
官方文档
- CrewAI 官方文档: Introduction - 持续更新
- CrewAI 官方文档: Agents - 持续更新
- CrewAI 官方文档: Tasks - 持续更新
- CrewAI 官方文档: Tools - 持续更新
- CrewAI 官方文档: Flows - v1.15+ 新增
- CrewAI 官方文档: Tracing - 持续更新
- [arXiv: Communicative Agents for Software Development](2305.14314) - 2023-05
开源项目
- crewAIInc/crewAI - 54,741 stars / 7,674 forks / MIT / 2026-07-02 更新 [200]
- crewAIInc/crewAI Releases - 最新 v1.15.2a2 (2026-07-01) / 稳态 v1.15.1 (2026-06-27) [200]
- crewAIInc/crewAI-examples - 官方示例集 [200]
- microsoft/autogen - 59,416 stars / 对比框架 [200]
- langchain-ai/langgraph - 36,264 stars / 对比框架 [200]
行业报道
- Lilian Weng: LLM Powered Autonomous Agents - 2023-06-23, 经典综述
社区讨论
- HN: Show HN - I built AI agents with CrewAI to automate my entire Gmail workflow - 2025-03-13, 26 points
- HN: Portia – A stateful Crew AI alternative - 2025-07-14, 19 points
- HN: CrewAI vs. AutoGen for running LLM-generated code - 2024-02-16, 14 points
- HN Algolia: "crewai" 搜索 - 持续聚合
对比基准 / 生态观察
- GitHub API: crewAIInc/crewAI 元数据 - 2026-07-02 拉取,54.7k stars / 7.6k forks [200]
- Hugging Face Blog - Multi-Agent 生态对比参考
本文由 AI 生成。内容基于公开资料整理,可能存在事实偏差,引用链接请以原始来源为准。