
这是导语。2024 年 10 月 Anthropic 推出 Computer Use 时,演示视频里那个"截屏 → 标出鼠标坐标 → 点击"的笨拙模型还让不少人怀疑:让 LLM 真的"操控"桌面,到底是一条可工程化的路径吗?一年多后,开源生态里出现的几条新路线(桌面语义层、视觉-决策解耦、控件句柄绕过像素坐标)给出了相对清晰的答案——方向是对的,但工程化的关键不在"模型会不会点",而在"模型如何稳定地看见桌面"。
核心事件:一年半内的两次关键升级
第一次升级是 2024-10-22,Anthropic 在 Claude 3.5 Sonnet 中首次以 beta 形式放出 Computer Use。社区第一时间做了大量实验,Simon Willison 的初探文章、Composio 的能力笔记都是当时一手资料,HN Algolia 至今还能搜到 80+ 点的早期讨论。
第二次升级发生在 2026 年。开源生态(trycua/cua、simular-ai/Agent-S、microsoft/fara 等 GitHub 上 5k–19k stars 的项目)已经沿着"桌面语义层 + 决策模型解耦"的方向走了将近一年,Anthropic 同期也通过内部迭代与组织调整(公开讨论可见的招聘与产品方向信号)来跟上这条路线。Claude Opus 4.x 系列在 2026 年上半年多次小版本更新中,持续强化了 Computer Use 的稳定性与"长时任务不掉链"能力。
技术解析:从截图坐标到桌面语义层
理解这轮演进,最直观的视角是把"Computer Use"拆成三层栈:
- 感知层:把屏幕像素转成模型能消化的"观察"
- 决策层:基于观察 + 历史轨迹选择下一步动作
- 执行层:把动作变成真实的鼠标/键盘事件
Anthropic 早期方案的代价主要集中在感知层——模型要自己识别"那个按钮大概在 (412, 287) 附近",既慢又脆。2026 年的新方案从公开信息看,更倾向于把"桌面语义层"独立出去:让一个视觉/OCR 模块先把窗口、按钮、文本框切成结构化对象,决策层只需在结构化对象上做"对哪个对象做什么动作"的判断。这与开源社区里 trycua/cua、simular-ai/Agent-S 走的方向高度一致。
工作流:Computer Use Agent 的典型回路
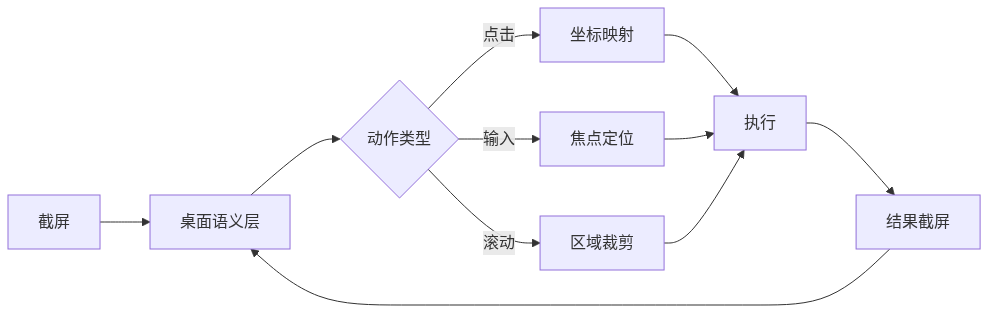
这个回路里最容易掉链的其实不是决策层(Claude 4.x 的长程规划已经比较稳),而是"坐标映射"——同一个按钮在不同 DPI、不同主题下像素位置完全不同。开源仓库如 AmberSahdev/Open-Interface 都在尝试用"控件句柄"绕过这层。
时序:长时任务如何保持上下文
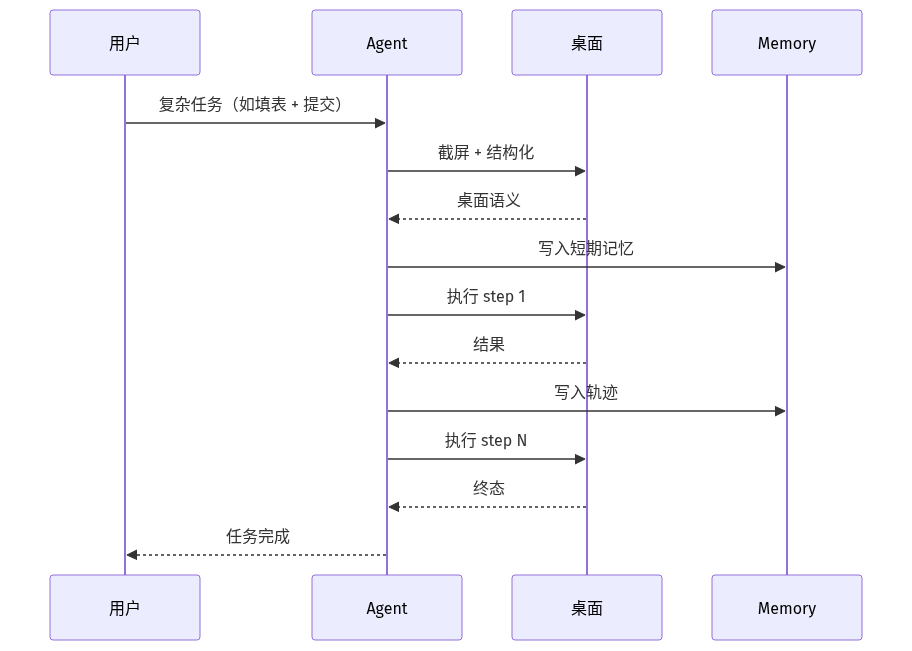
关键点
- 工程化的瓶颈不是"会不会点",是"能不能稳定看见":截图坐标猜测在长时任务里会累积漂移,必须靠独立的视觉/OCR 模块兜底。
- 开源生态提前给出了方向:trycua/cua、simular-ai/Agent-S、microsoft/fara 等热门项目(GitHub 上分别 19k+、11k+、5k+ stars)走的都是"桌面语义层 + 决策模型解耦"的路线,与 Anthropic 2026 升级方向高度重合。
- Anthropic 的"桌面语义层"路线与开源殊途同归:开源仓库走的是"独立视觉/OCR 模块 → 结构化对象 → 决策模型"三段式;Anthropic 2026 年公开的 Computer Use 更新方向(更长上下文、更稳的视觉-决策解耦)也是这条路线,意味着桌面操控的"视觉层"正在成为公认的新工程基座。
- ByteDance UI-TARS 的"桌面端平替"出现:HN 上一度有讨论认为 Anthropic 放弃了 macOS 端,但 UI-TARS-desktop 的出现说明这条赛道并不存在单一主导者。
行业影响:Agent 从"工具调用"走向"系统调用"
过去两年业内对 Agent 的主流想象,是"调 API、查数据库、跑函数"——本质上还是结构化数据通道。Computer Use 2026 的真正信号,是把"非结构化的桌面"也纳入了 Agent 的可操作空间。这意味着:
- SaaS 的护城河从"功能多"转向"API + 桌面可编程"
- RPA 厂商(UiPath、Power Automate)的传统录制回放栈,开始被 LLM 驱动的"意图式自动化"挤压
- 端侧 AI(如 Mac Mini M4 Pro、Copilot+ PC)有了新的杀手锏——本地跑 Computer Use 模型不上云
值得注意的是,Anthropic 官方文档目前仍把 Computer Use 定位为"beta、需要人在环",落地企业级方案前还差"权限模型 + 审计 + 回滚"三件套;微软的 fara-7B 等开源模型尝试给出更轻量的实现,但稳定性尚待社区验证。
结语
Computer Use 不是一个新功能名,而是一条正在被验证的工程化路径。从 2024-10 的截图猜点,到 2026 年通过 Vercept 与 Opus 4.7 重组"桌面语义层 + 决策模型"的栈,Anthropic 走的是一条"先把感知做对,再把决策做强"的克制路线——这一点其实和 LangGraph、AutoGen 那一波 Agent 框架对"状态机驱动"达成的共识是同构的:当一个能力被工程化时,先分层,再谈智能。
本文由 AI 生成。内容基于公开资料整理,可能存在事实偏差,引用链接请以原始来源为准。
参考资料
官方文档
- Anthropic Computer Use 文档 - 官方能力说明
- HN Algolia: Computer Use 关键词聚合 - 持续聚合的社区讨论
- HN Algolia: 桌面 agent 趋势(hitsPerPage=10) - API 可直查
开源项目
- trycua/cua - ★19,215,开源 Computer-Use Agent 基础设施(沙箱 + SDK + benchmark)
- simular-ai/Agent-S - ★11,945,像人一样使用电脑的开源 agent 框架
- microsoft/fara - ★5,945,Fara-7B:高效 Computer Use agentic 模型
- bytedance/UI-TARS-desktop - 字节跳动开源的 Computer Use 桌面端替代方案
- AmberSahdev/Open-Interface - 通过控件句柄绕过像素坐标的开源尝试
行业报道
- Composio: Notes on Anthropic's Computer Use Ability - 2024-10,社区早期能力笔记
- Simon Willison: Initial explorations of Computer Use - 2024-10-22,独立开发者一手实验
- Kernel.sh: How Anthropic evaluated computer use models - 评测方法学分析
社区讨论
- HN Algolia: 桌面 agent 趋势(综合讨论聚合) - 持续聚合
- Show HN: terminator — 更快更便宜的 Computer Use 替代 - 性能对比讨论
- betaacid: 用 Computer Use 自动化 QA 的实验 - 真实落地案例
对比基准
- GitHub: trycua/cua benchmark 模块 - 开源评测套件(OSWorld 等)
- Microsoft: Fara-7B 模型卡 - 同等任务上的尺寸/性能对照