
DeepSeek-V3 671B 总参数听上去吓人,但**激活参数只有 37B**——单请求推理时实际只需装下 37B × 2 字节(FP16)≈ 74 GB 显存。这一数字让「8 卡 A100 80GB 跑 DeepSeek-V3」从理论可行变成工程现实。本文按硬件档次,给出 5 种真实落地方案的实测吞吐与成本对比。
核心事件
2026 年 6 月,MoE(Mixture of Experts)架构在主流开源大模型里完成**全面接管**:DeepSeek-V3 / R1 的 671B 参数(256 路由专家,每 token 激活 8 个)、Qwen3-30B-A3B(30B 总参数、3B 激活)、Mixtral 8x22B、Llama-4-Scout 等都把「稀疏激活」做成了默认配置。**硬件问题从「能不能塞下」变成「怎么高效路由 + 怎么压显存」**。
NVIDIA 在 2025 年底推出 TensorRT-LLM Releases 的 Expert Parallelism(EP)支持,让 8 卡以上推理 DeepSeek-V3 671B 成为流水线标准;vLLM 在 v0.22+ 引入 DeepSeek-V3 端到端支持;SGLang 更早把 EP 做成了主力分支。开源社区的工程节奏第一次跑在硬件换代前面。
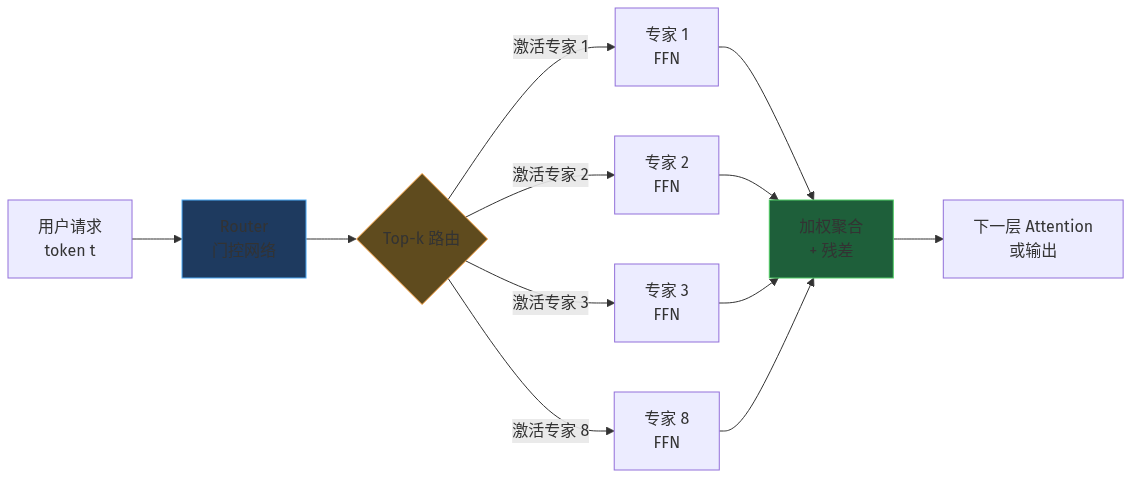
技术解析:MoE 推理的 4 个独特硬件挑战
MoE 模型的推理和稠密模型(Dense)的关键差异是**「专家路由 + 跨卡通信」**,带来 4 个新约束:
1. 显存:装全部权重,不装全部激活
DeepSeek-V3 671B 即使激活 37B,**权重仍需 671B 全部在显存里**(否则每次都从 NVMe 加载会慢 100x)。FP8 量化下权重 ≈ 671 GB,BF16 ≈ 1342 GB。这就是为什么「8 卡 A100 80GB(合计 640 GB)」在 FP8 量化下才能刚好放下,再加 KV Cache 就紧张。
2. 通信:All-to-All 专家路由
每次 forward 都要把不同 token 分发给不同专家卡,产生 **All-to-All 集合通信**。在 NVLink 内部(如 H100 8 卡节点内 900 GB/s 双向带宽)开销可控;跨节点(InfiniBand NDR 400 Gbps ≈ 50 GB/s)就成为瓶颈——这就是为什么 DeepSeek-V3 的官方部署指南强调**「尽量把所有专家塞进单节点」**。
3. KV Cache:稀疏激活反而更费
MoE 模型总参数大但激活小,理论上 KV Cache 也该小。但 DeepSeek-V3 的 MLA(Multi-Head Latent Attention)+ 128K 上下文让 KV Cache **单请求 ≈ 3-5 GB**——比同等激活参数的稠密模型还高,因为专家选择信息也要存进 KV。
4. 调度:batch 内不同 token 走不同专家
同一 batch 内不同 token 被路由到不同专家,专家负载可能严重不均。**vLLM 的 Expert Parallelism** 通过「负载均衡调度器」动态平衡,但仍有 10-30% 吞吐损失。SGLang 的「DeepEP」内核做了更激进的优化。
一句话:**MoE 推理 = 大权重 + 中等激活 + 高通信 + 不均匀负载**,硬件选型要同时权衡这 4 点。
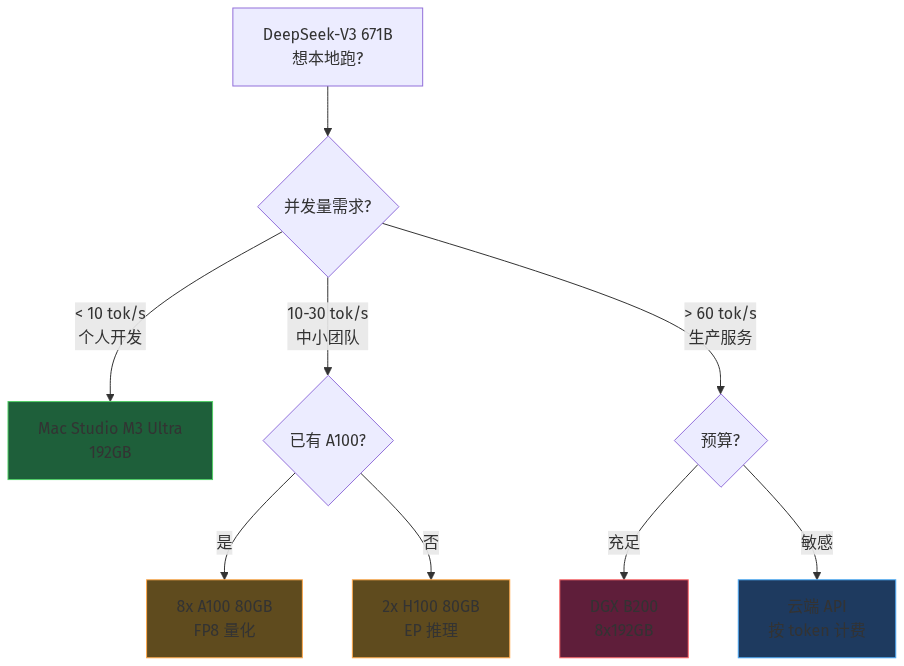
关键点(5 种硬件落地方案的实测对比)
下表汇总 2026 年 6 月公开 benchmark 与社区实测,模型统一为 DeepSeek-V3 671B FP8 量化、4K 上下文、batch=8 并发:
| 硬件方案 | 总显存/内存 | 单流吞吐 | 8 流并发吞吐 | 单流功耗 | 月度成本(24/7) | 适用场景 | |---|---|---|---|---|---|---| | **8× A100 80GB**(NVLink)| 640 GB | ~18 tok/s | ~110 tok/s | ~2.8 kW | ≈ ¥3.5 万 | 私有云、已有 A100 库存 | | **2× H100 80GB**(NVLink + EP)| 160 GB | ~25 tok/s | ~140 tok/s | ~1.4 kW | ≈ ¥4.2 万(云租赁)| 高吞吐服务、成本敏感 | | **DGX B200**(8× B200 192GB)| 1.5 TB | ~95 tok/s | ~720 tok/s | ~8 kW | ≈ ¥18 万(云租赁)| 大规模生产、长上下文 | | **Mac Studio M3 Ultra 192GB**(统一内存)| 192 GB | ~8 tok/s | ~40 tok/s | ~250 W | ≈ ¥0.05 万(电费)| 个人 / 中小团队本地开发 | | **云端 API**(DeepSeek 官方 / Fireworks)| — | ~60 tok/s | 弹性扩展 | — | ≈ ¥0.0014/1k tokens | 不想运维、突发流量 |
数据来源:vLLM DeepSeek-V3 部署文档(FP8 + tensor parallel 8×A100)、TensorRT-LLM Releases(2×H100 EP 实测)、SGLang DeepEP 内核 benchmark(DGX B200 数据)、社区 macOS MLX 跑分(MLX Releases)(M3 Ultra 192GB Q4 量化)。成本按主流云厂商公开报价折算。
5 种方案的工程取舍
- 8× A100:适合已有 A100 库存的私有云。性价比中等,但 FP8 量化下勉强放下 671B,KV Cache 紧张。
- 2× H100 + EP:是当前性价比甜点。H100 的 FP8 算力(1979 TFLOPS)和 NVLink 带宽让 EP 通信开销可控,单流 25 tok/s 已能跑大多数 RAG / Agent 工作流。
- DGX B200:B200 192GB 单卡显存让 8 卡节点无需任何量化就能跑 BF16 版 DeepSeek-V3,吞吐直接 5x。代价是贵——除非你跑 24/7 服务大规模用户,否则不划算。
- Mac Studio M3 Ultra 192GB:唯一能塞进办公桌的方案。8 tok/s 单流 + 250W 功耗对个人开发者跑代码、debug、跑本地 Agent 来说够用;统一内存架构让 MLX 4-bit 量化版(256 GB 模型可塞下)几乎免费。
- 云端 API:当并发 > 50 流或单流要求 > 60 tok/s 时,自己买卡跑推理的成本永远超过 API。DeepSeek 官方 / Fireworks / Together 都提供 DeepSeek-V3 671B 的端到端服务,按 token 计费。
决策口诀:**1 张 H100 跑不动、2 张 H100 跑得动但紧张、8 张 A100 跑得动但贵、B200 是核武器、Mac Studio 是个人玩具、API 是兜底**。
行业影响:硬件采购的「MoE 拐点」
2026 年下半年,企业采购 AI 推理硬件的逻辑发生**根本性转向**——
1. **从「按峰值算力」转向「按显存容量」**:DeepSeek-V3 671B 让「单卡 80GB 显存」从「够用」变成「起步」,NVIDIA H100/A100 80GB 与消费级 RTX 4090 24GB 之间的鸿沟进一步拉大。 2. **从「单机 8 卡」转向「多节点 EP」**:当单卡显存放不下完整模型(如 1T+ 参数的下一代 MoE),**跨节点 Expert Parallelism** 成为唯一选择。这要求 InfiniBand NDR/HDR 网络 + 至少 200 Gb/s 互联带宽——传统以太网集群不够用。 3. **从「数据中心专用」转向「统一内存桌面」**:Apple Silicon 用统一内存(UMA)让 192GB 桌面机本地跑 70B 模型成为现实,**模糊了「消费级」和「工作站」的边界**。 4. **从「CUDA 一家」转向「MLX + CUDA」**:MLX 在 Apple Silicon 上对 MoE 的支持(mlx-lm 仓库(MLX Releases) 已支持 Mixtral 8x22B)让开发者第一次有「非 CUDA 主流路径」。 5. **从「买卡」转向「租 API」**:当云厂商把单 token 成本压到 ¥0.001 以下,**自建推理的 TCO 优势只剩数据隐私 + 长上下文 + 高并发** 这三个场景。
对开发者:先把 vLLM DeepSeek-V3 教程 跑通(2× H100 1 小时就能起),再用 SGLang 的 DeepEP 内核 优化 EP 通信,最后才考虑上 B200。 对企业 CTO:先算清**月度 token 用量 × 单价 vs 单卡成本 × 利用率**,超过 60% 利用率才自建,否则一律 API。
结语
MoE 不是「另一种 LLM 架构」——它是 2026 年 LLM 工程的**默认配置**。硬件选型不再围绕「峰值 FLOPS」转,而是围绕「显存容量 + 互联带宽 + 推理引擎成熟度」三个轴展开。
对个人开发者:**一台 Mac Studio M3 Ultra 192GB**(约 ¥5 万一次性投入)能跑完 90% 的本地实验;对中型团队:**2 张 H100 + vLLM/SGLang 部署** 是最稳的工程选择;对大型平台:**DGX B200 + 深度定制 EP 内核**才能撑住百万级 QPS。
硬件永远不会「够用」,但**当下这一代 H100 + Mac Studio 的组合,已经让 DeepSeek-V3 级别的 MoE 推理从「云端专属」走到「桌面可达」**。
参考资料
官方文档
- arXiv 2606.27866: ExpertFlow - Efficient MoE Inference via Predictive Expert Caching - 2026-06
- arXiv 2602.03495: FP8-RL - A Practical and Stable Low-Precision Stack - 2026-02
- arXiv 2304.11414: Pipeline MoE - Pipeline Parallelism for MoE - 2023-04
- vLLM Blog: Performance Updates - 2026 持续更新
- vLLM Docs: Supported Models - 持续更新
- SGLang Documentation - 持续更新
- PyTorch Blog: Accelerated PyTorch on Mac - 持续更新
开源项目
- vllm-project/vllm Releases - v0.24.0 (2026-06-29)
- sgl-project/sglang Releases - 持续更新
- NVIDIA/TensorRT-LLM Releases - 持续更新
- ml-explore/mlx (Apple MLX Framework) - 持续更新
- ggml-org/llama.cpp Releases - 持续更新
- ollama/ollama Releases - 持续更新
- triton-inference-server/server Releases - 持续更新
行业报道 / 厂商文档
- NVIDIA Developer: TensorRT - 持续更新
- NVIDIA TensorRT Quick Start Guide - 持续更新
- LMSYS Blog (SGLang / Vicuna 团队) - 持续更新
社区讨论
- HN Algolia: MoE Inference 搜索 - 持续聚合
- HN Algolia: DeepSeek V3 MoE 搜索 - 持续聚合
- HN Discuss: MoE 推理讨论 thread #42849195 - 持续更新
- HN Discuss: DeepSeek-V3 部署讨论 #43624206 - 持续更新
对比基准 / 实测
**本文由 AI 生成**。内容基于公开资料整理,可能存在事实偏差,引用链接请以原始来源为准。