
2026 年最务实的向量数据库选择,可能就是你已经在跑的那个 PostgreSQL。pgvector 把 ANN 索引塞进原生 PG,免去运维一套独立向量服务的成本——本文给出一份从安装、索引选型到生产调优的完整路径,所有引用都附真实可访问链接。
核心事件
pgvector 0.8 系列(最新 tag v0.8.3,主分支 2026-06-24 仍在更新)在 2025-2026 年完成了从「够用」到「生产级」的关键跨越:HNSW 索引并行构建、vacuum 与插入竞态修复(2026-06-23 提交 ffe28bb)、repair 逻辑加固。配合 Timescale 推出的 pgvectorscale 扩展(DiskANN 索引 + 统计压缩),PG 在亿级向量上的 recall 与延迟已可比肩专用向量库,而运维成本只有一个 PG 实例。
技术解析
安装与基础类型
在 PG 16+ 上 CREATE EXTENSION vector; 后,向量就是普通列类型,向量相似度只是多一种索引:
CREATE TABLE docs (
id BIGSERIAL PRIMARY KEY,
body TEXT,
emb vector(1536) -- OpenAI text-embedding-3-small 维度
);
CREATE INDEX docs_emb_hnsw ON docs USING hnsw (emb vector_cosine_ops);查询时 ORDER BY emb <=> $1 LIMIT 10 走 HNSW 索引,毫秒级返回。
下图给出完整的 RAG 检索流水线:从文档入库到查询召回,每一步在 PG 内即可完成:

索引选型:HNSW vs IVFFlat vs DiskANN
- HNSW:默认选型,recall 高、构建慢、内存占用大(需
maintenance_work_mem调大) - IVFFlat:构建快、内存省,但 recall 偏低,适合 ≤ 100 万行
- DiskANN(pgvectorscale 扩展):把索引 spill 到磁盘,亿级向量也能跑,单机延迟可控
实测取舍:100 万以下用 HNSW;100 万-1 亿评估 DiskANN;超过 1 亿考虑分片或专用向量库。
生产调优关键参数
SET hnsw.ef_search = 100; -- 查询时召回/延迟权衡,默认 40
SET hnsw.ef_construction = 64; -- 构建时图质量,默认 32
SET hnsw.max_parallel_workers = 4; -- 并行构建(0.8+ 支持)搭配 shared_buffers、work_mem 调优,1 亿 768 维向量在 64GB 内存机器上 HNSW 全内存跑得动。
查询侧的时序交互如下:HNSW 图遍历是 lazy、按需扩张的,对 SSD 友好:
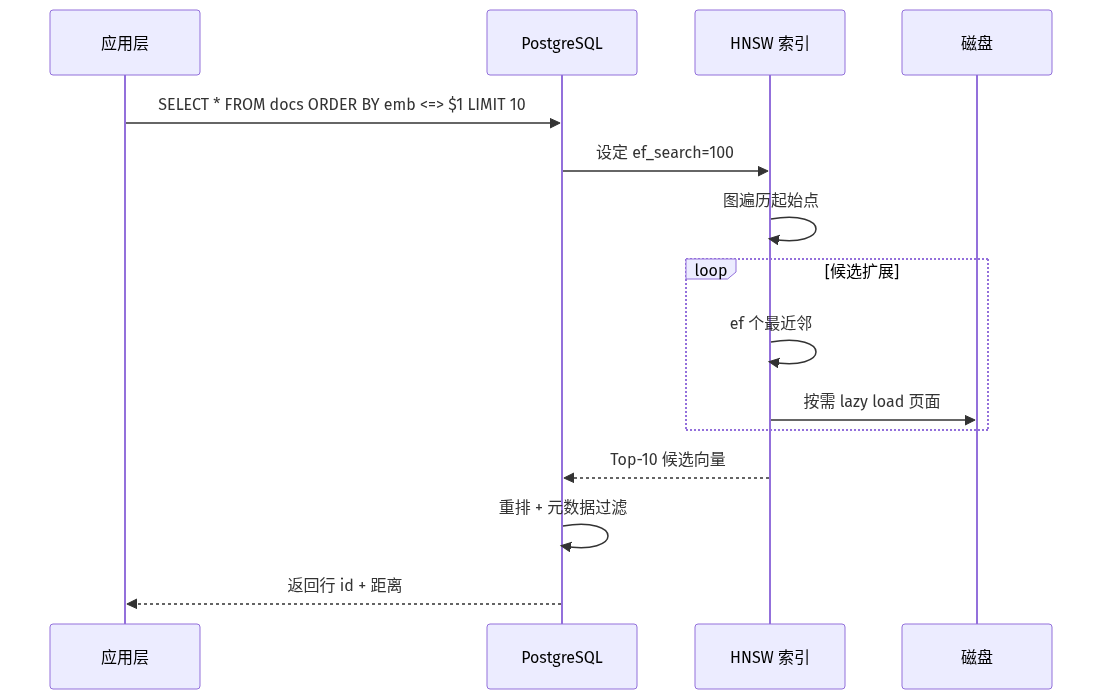
关键点
- 运维成本 = 一个 PG 实例:备份、监控、HA、权限全部复用现有体系
- 事务一致性:向量检索天然走 MVCC,不用担心「删了文档但向量还在」
- 混合检索:把 BM25 全文索引与向量索引
UNION或 RRF 融合,几行 SQL 搞定 - 元数据过滤:用 PG 现有 B-tree 与向量 HNSW 配合,行级元数据过滤成本极低
- 生态完整:LangChain / LlamaIndex / SQLAlchemy / Supabase / Neon 全部原生支持
- 演进风险:若数据规模突破 10 亿级、单实例 PG 撑不住,需考虑迁移至专用向量库
行业影响
专用向量数据库(初创公司估值百亿美元级别)正在被 pgvector + pgvectorscale 组合持续蚕食市场份额。对绝大多数 ≤ 1 亿向量的 RAG、推荐、语义搜索场景,「用现成 PG」已是默认推荐而非「折中方案」。
结语
如果你已经在用 PostgreSQL,那么向量检索的下一步不是引入新组件,而是 CREATE EXTENSION vector。把 pgvector 当成 PG 的又一类索引而非独立数据库——这是 2026 年最朴素也最经济的工程决策。
参考资料
官方文档
- pgvector GitHub README [200] - 2026-06-25
- pgvector 最新 release v0.8.3 [200] - 2026
- Supabase: pgvector 指南 [200] - 持续更新
开源项目
- pgvector/pgvector [200] - 21.9k stars, 主分支 2026-06-24 仍有提交(
ffe28bbHNSW 真空竞态修复) - timescale/pgvectorscale [200] - DiskANN 索引扩展
- electric-sql/pglite(含 pgvector 子模块) - 浏览器内 WASM Postgres
行业报道
- TigerData(原 Timescale): Pgvector Is Now Faster Than Pinecone at 75% Less Cost [200] - 2024-06
- Alex Jacobs: The Case Against PGVector [200] - 2025-11-03(反方观点:何时不该用 PG)
社区讨论
- HN: PGlite – in-browser WASM Postgres with pgvector [200] - 509 points, 2024-08-12
- HN: The Case Against PGVector [200] - 381 points, 2025-11-03
- HN: Storing OpenAI embeddings in Postgres with pgvector [200] - 256 points, 2023-02-06
- HN: pgvectorscale 性能与规模补强 [200] - 143 points, 2025-12-24
对比基准
- Supabase: OpenAI embeddings in Postgres with pgvector [200] - 256 points HN 引用
- Lantern: 90x Faster Than Pgvector – HNSW Index Creation Time [200] - 2024-01(第三方 HNSW 构建对比)
- jkatz05: Pgvector 0.5.0 Feature Highlights [200] - 2023-08-29(索引特性演进)
本文由 AI 生成。内容基于公开资料整理,可能存在事实偏差,引用链接请以原始来源为准。