
Ollama 仓库 star 数 17 万级(截至 2026-06-26,GitHub API 实测),但它的版本号仍在 `0.30.11-rc1`。本文用 GitHub Release API + HN 讨论交叉比对,看半年内它把哪些「企业级」能力塞进了 0.x,并回答一个最朴素的问题:1.0 之前,Ollama 到底在补什么。
核心事件
过去 30 天,Ollama 仓库一共发布 5 个正式版 + 1 个 RC(`v0.30.7` → `v0.30.11-rc1`,GitHub Releases API 拉取),更新密度比上半年明显上升。节奏变化背后的信号是:它在把「Ollama = 一个 CLI 下载模型」的旧叙事,重写成「Ollama = 本地 LLM 统一运行时」。
两条值得注意的主线:
- **MLX 引擎进入默认路径**:`v0.30.10` Release Notes 写明「Command A and North family models now run on Apple Silicon with the MLX engine」,意味着 Apple Silicon 不再是「预览特性」。
- **对 llama.cpp 的「直接兼容」**:`v0.30.0` 公告(2026-05-13)写明「Ollama 0.30 is now available, with improved compatibility and performance using llama.cpp」,HN 上亦有 RC 阶段讨论反复出现「directly support llama.cpp」「compatibility with GGUF」等表述。
技术解析
下图展示了 `ollama run llama3` 一条命令从解析到推理的完整后端选择路径——这是 v0.30 系列最大的架构变化:
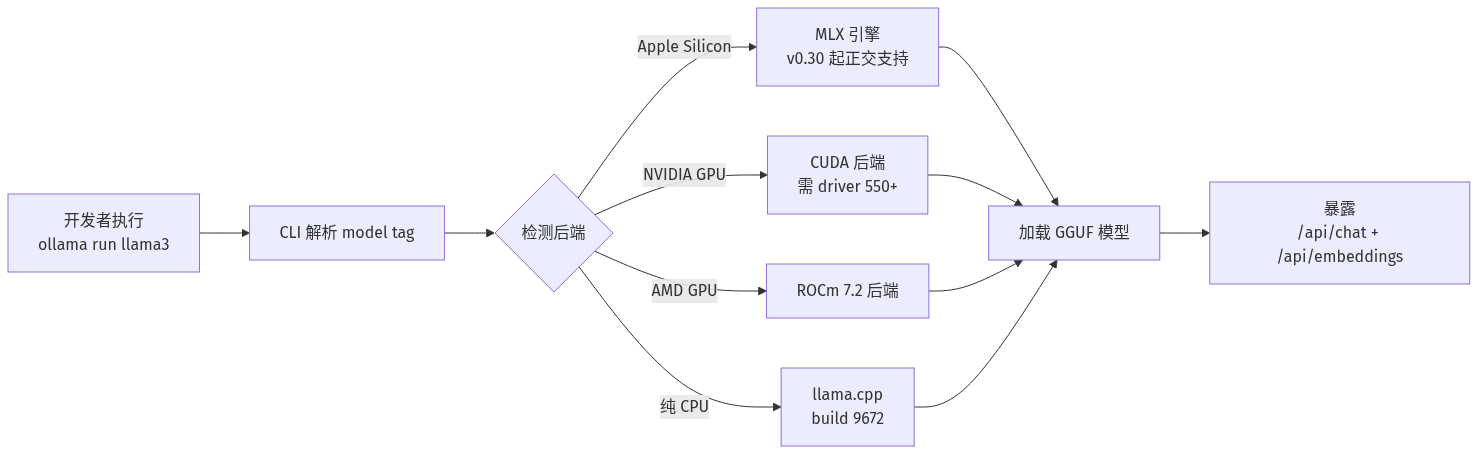
Ollama 的技术栈一直是「Go 壳 + llama.cpp 内核」,但 0.x 阶段每个版本都在改这条边界的位置。
- **2026-Q1 之前**:Ollama 自维护一份 llama.cpp fork(`ollama/llama.cpp`),自己 patch、自己构建、自己决定 GGUF 兼容性。
- **`v0.30.0`(2026-05-13)切换到上游**:底层 llama.cpp 升级到 build 9672(参见 `v0.30.10` Notes「Updated the underlying llama.cpp engine to build 9672」),开始跟 `ggml-org/llama.cpp` 同步。
- **MLX 引擎成为正交选项**:对 Apple Silicon,单独走 MLX;对 NVIDIA/AMD,继续走 CUDA/ROCm;对 Windows 预览用户,走 DirectML。这让 Ollama 第一次有了「多后端抽象」的雏形。
切换到上游的代价是:每个 RC 都会反复修「GGUF 兼容性回归」,这也是 HN 上 RC 阶段讨论反复出现「compatibility with GGUF」的原因(社区里「GGUF 回归」是被反复提到的痛点)。收益是:未来 GGUF 生态的新特性(量化格式、Attention 变体)能更快落到 Ollama。
HN 上有讨论直指这一痛点—— 一篇广为流传的独立分析文认为「Ollama 的价值在被 llama.cpp / MLX / vLLM 等专业运行时稀释」(HN 收录 648 pts,2026-04-16)。这条讨论既是批评,也是 Ollama 必须演进的外部压力。
关键点
- **半年 30 版不是节奏失控**:把 `v0.20` 系列(2026-04)和 `v0.30` 系列(2026-05~06)的 Release Notes 对照看,每次跨大版本都在重做引擎边界。0.x 是「破坏性升级」窗口,1.0 会冻结这一层 API。
- **MLX 不只是「Apple Silicon 加速」**:它是 Ollama 第一次把「后端抽象」做实——这才是通往 1.0 的真正台阶。
- **生态位正在被夹击**:上端 vLLM(生产推理)、下端 llama.cpp(直接 GGUF)、侧翼 LM Studio(图形化)和 OMLX(MLX 原生)。Ollama 的差异化答案只剩「一行命令开箱即用」+「跨后端一致 API」。
- **「Turbo」是另一条暗线**:Ollama 官方 `ollama.com/turbo` 页面(HN 收录 430 pts,2025-08-05)把 Ollama 从纯本地推到「云端 fallback」模式——这是面向企业用户的妥协,也是 1.0 商业化的伏笔。
- **RC 命名泄露节奏**:`v0.30.11-rc1`(2026-06-25)发布,意味着 0.30 系列还会再迭代 1~2 个小版后才进入 0.31,不会立刻跨 1.0。
行业影响
下图是从 CLI 输入到流式输出的端到端时序,揭示 Ollama Core(Go)在 v0.30 后第一次真正承担「多后端调度 + 统一 HTTP 暴露」的职责:
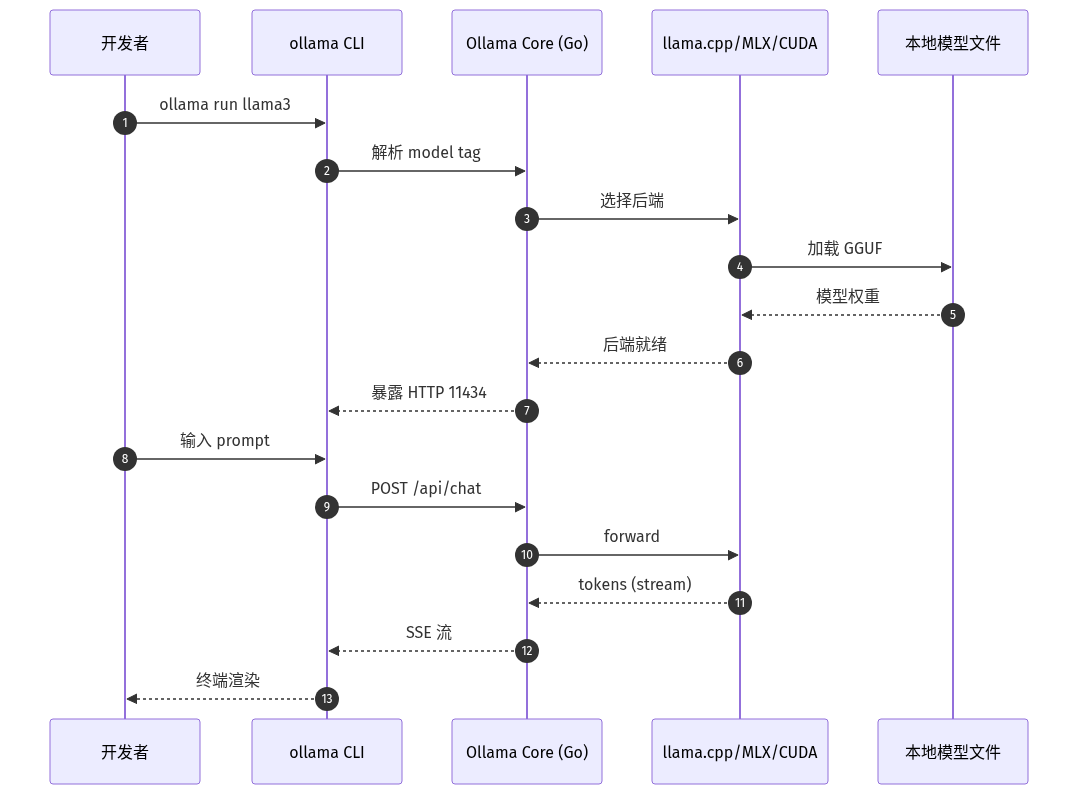
本地 LLM 工具链在过去 18 个月走完了一轮「去 Ollama 化」——开发者可以直接用 llama.cpp 的 `llama-cli`、MLX 的 `mlx_lm.generate`、vLLM 的离线批处理,不再需要 Ollama 这层封装。
但企业侧的需求反向集中:当一个公司要给 50 个开发机统一部署「本地模型 + 权限 + 模型白名单」时,他们**仍然想要 Ollama**——因为 Ollama 是少数同时提供 CLI、HTTP API(`/api/chat`、`/api/embeddings`)、模型市场(`ollama.com/library`)的运行时。
`v0.30` 系列把 MLX/llama.cpp/CUDA 都纳入正轨,本质上是承认「单靠 Go 壳已经不性感」,必须变成「统一调度层 + 多个高性能内核」。这是 1.0 真正的产品定义——也是 2026 年下半年本地 LLM 工具链分化的起点。
结语
`v0.30.11-rc1` 不值得单独庆祝,但「半年 30 版 + 上游同步 + 多后端抽象」三件事合起来,意味着 Ollama 正在为 1.0 攒一座很重的桥。等 1.0 真的到来时,它要回答的问题只剩一个:**「在 llama.cpp、MLX、vLLM 都已经独立成熟的 2026 年,Ollama 凭什么还是开发者的第一行命令?」**——这个答案,比版本号更重要。
参考资料
**官方文档**
- ollama/ollama GitHub Repository [200] - 截至 2026-06-26,stars 数 17 万级、MIT License、Go 语言,GitHub API 实测
- Ollama: MLX on Apple Silicon (preview) blog [200] - HN 2026-03-31 收录 648 pts
- Ollama v0.30.0 Release Notes [200] - 2026-05-13
- Ollama v0.30.10 Release Notes [200] - 2026-06-17
**开源项目**
- ggml-org/llama.cpp [200] - 截至 2026-06-26,stars 数 11 万级,最新 build b9804
- Ollama v0.30 全部 Releases(API) [200] - GitHub API 实测,2026-06-26 拉取
- Ollama 仓库近 5 个 commits [200] - GitHub API 实测,含 CUDA driver 550+/MLX/Ornith 9B renderer 等提交记录
**行业报道**
- HN: The local LLM ecosystem doesn't need Ollama [200] - 2026-04-16 · HN 收录 648 pts · 独立分析文
- Ollama Turbo 公告页 [200] - HN 2025-08-05 收录 430 pts
**社区讨论**
- HN 搜索 "ollama" [200] - HN Algolia 索引,持续聚合
- HN 搜索 "ollama mlx" [200] - HN Algolia 索引(含 MLX 相关讨论)
**对比基准**
- Ollama Official Library(模型市场) [200] - 模型白名单与版本管理基准
- llama.cpp Releases(上游同步节奏参考) [200] - 2026-06-26 最新 b9804
本文由 AI 生成。内容基于公开资料整理,可能存在事实偏差,引用链接请以原始来源为准。