
把 Agent 跑通只是第一步,让它"在出问题的时候能定位到点"才是生产化的关键。本文走通一个最小闭环:从一个会调工具的 LangGraph Agent 开始,到在 LangSmith 里看到完整 trace、定位一次工具调用失败、再设置一个 production alerting,全程不到 30 分钟。
核心事件
2026 年是 Agent 走向生产的一年。LangChain 团队在 2026 年 5 月正式发布 LangSmith Fleet(前身 Agent Builder),把 tracing + evaluation + deployment 整合成一个统一控制台;同时 v0.9.x 系列的 langsmith-sdk 持续发布,6 月 22 日发布的 v0.9.0 重写了 run-tree 数据结构,让长会话(multi-turn)的 trace 拼接开销降到原来的数分之一。配套地,官方文档(docs.langchain.com/langsmith/observability)明确把 LangSmith 定位为"framework-agnostic"——意味着即使你不跑 LangChain,OpenAI Agents SDK、CrewAI、Pydantic AI、Vercel AI SDK 同样可以接到同一个 trace 后端。这对正在做技术选型的团队是个关键信号:监控层开始和编排框架解耦了。
技术解析
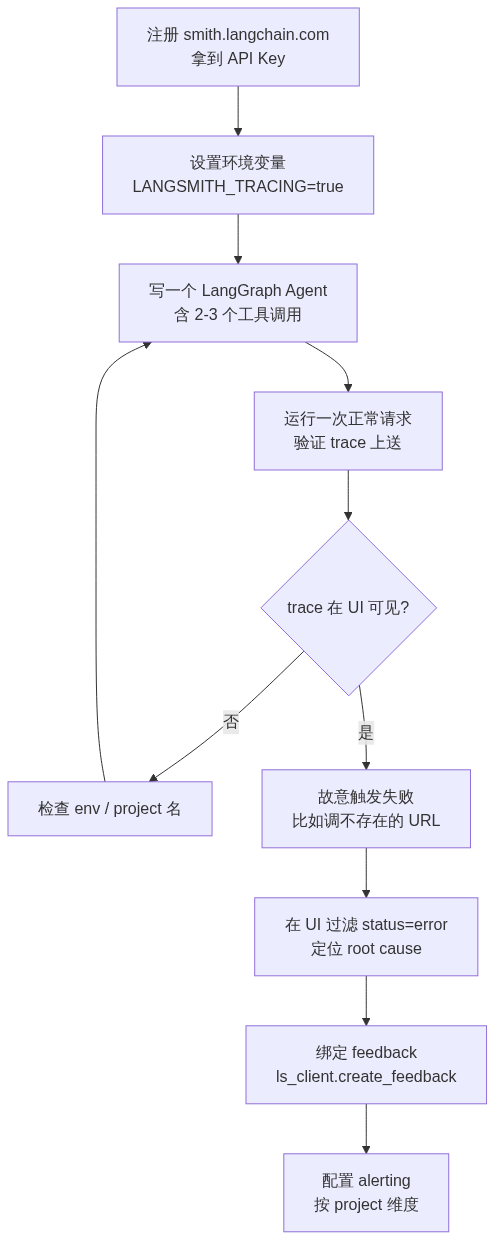
最小闭环需要 4 个组件:(1) 一个 LangSmith 账号 + API key,(2) 一个有工具调用能力的 LangGraph Agent,(3) 一段把 trace 推到 LangSmith 的初始化代码,(4) 一次故意的失败来验证 trace 真的能定位到问题。
第一步在 smith.langchain.com 注册账号(不需要信用卡),拿到 API key 后在环境变量里写 LANGSMITH_TRACING=true 和 LANGSMITH_API_KEY=...。只要环境变量设了,@traceable 装饰的函数和 LangChain/LangGraph 自动 trace 的链路会全部上送,不需要改业务代码。 这是 LangSmith 相比自建 OpenTelemetry collector 最省事的地方。
第二步的 Agent 不必复杂——一个会调两三个工具的 LangGraph 图就够演示了。关键是每个节点(LLM 调用、retrieval、tool)都要进入 trace 树,所以建议用 LangGraph 1.0 而不是 0.x:1.0 起每个 node 的入参、出参、latency、token 计数都会自动出现在 trace 的对应 run 上。
第三步是用 SDK 主动打 feedback:ls_client.create_feedback(run_id, key="user-score", score=1.0)。这一步把"用户评分"和"那次具体 run"绑起来,后续做离线评估、找回归样本都靠它。
第四步最容易忘——故意构造一次失败。比如让 Agent 调一个不存在的 URL,或者在 prompt 里塞一个明显违和的输入。然后去 UI 过滤 status=error,展开那条 trace,看 root cause 是 retriever 召回为空、还是 LLM 选错了 tool、还是 tool 返回的 schema 校验没过。LangSmith 的 trace 树把这三类失败用不同颜色标出来,比看 200 行日志快得多。
关键点
- 环境变量优先于代码:
LANGSMITH_TRACING=true一开,所有 LangChain/LangGraph 调用自动上送;不要在每个项目里手动初始化 client。 @traceable不是只能装饰 LLM 调用:任何你想观测的 Python 函数都可以加(包括外部 API wrapper、数据预处理),trace 会自动嵌套。- project 维度先于 thread 维度:在 LangSmith 里,project 是顶层容器;thread(一个完整对话)挂在 trace 下。监控告警建议按 project 维度配。
- 失败 trace 是金矿:error 状态的 trace 会被 LangSmith 自动聚类("Recurring Issues"),找出反复出现的根因,不要只盯 success rate 曲线。
- evaluations 不是离线专属:LangSmith 支持在线 LLM-as-judge evaluator,对每条生产 trace 实时打 quality 分;这比写一堆单元测试更接近真实分布。
实战步骤图
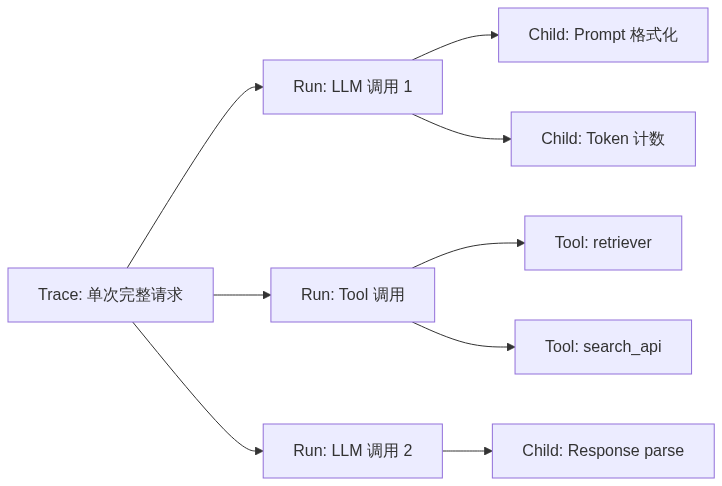
下面用 mermaid 把整个 30 分钟的流程画出来。注意 trace 树的关键在于 run 的层级关系:每次 Agent 推理产生一个 root run,下面挂 LLM run、tool run、retriever run。
trace 数据结构图
官方文档把 trace 定义为"a collection of runs",run 之间通过 parent_run_id 形成树。这是理解 LangSmith 所有 UI 的基础:
行业影响
LangSmith 在 2026 年和 Langfuse、Arize Phoenix、Laminar 一起构成了"Agent 监控四强"。从社区反馈(HN Algolia 上 langsmith 搜索有 95 分高赞讨论 RAG Logger 这种开源替代品)看,主流分歧已经不是"要不要做观测",而是"自建 OpenTelemetry + 自建 dashboard"还是"接一个 SaaS"。对中小团队后者更省人力;对合规要求严的大型组织前者更可控,但维护成本不止 1 个 FTE。
结语
如果你正在把第一个 Agent 推到生产,今天花 30 分钟配 LangSmith 比写一堆 print 调试强 10 倍。链路可视化 + 失败聚类 + feedback 绑定这三件事一旦就位,后续做 A/B 评测、回归检测、cost 优化全都有数据底座。LangSmith 的免费层对个人开发者和小团队够用,等 trace 量起来了再考虑付费 tier 或自建 OpenTelemetry 导出。
参考资料:
官方文档
- LangSmith Observability 概览 - 官方文档主入口,覆盖 tracing/dashboard/integrations
- LangSmith Observability 概念(trace / run / thread / project) - 数据模型定义
- Trace an LLM application 教程 - 官方 step-by-step 教程
- LangChain 官方博客:LangSmith GA 公告 - GA 时点特性说明
- LangChain 官方博客:LangSmith 发布公告 - 早期公告
开源项目
- langchain-ai/langsmith-sdk - 官方 Python/JS SDK(937 stars,2026-06 持续更新到 v0.9.x)
- langchain-ai/langgraph - LangGraph 框架(35.7k stars,与 LangSmith tracing 默认集成)
- Brandon-c-tech/RAG-logger - HN 上 95 分高赞的开源替代品
行业报道
- Metacto: What is LangSmith? 2026 完整指南 - 第三方 2026 横评,覆盖 LangSmith Fleet / pricing / 与 Langfuse/Helicone/Arize Phoenix 对比
- Laminar: Top 6 Agent Observability Platforms (2026) - 头部 6 家平台开发者视角排名
- Latitude: Best AI Agent Observability Tools 2026 - 11 平台对比,重点 multi-turn tracing
- MLflow: Agent Observability 2026 开发者指南 - MLflow 团队视角的定义与最佳实践
社区讨论
- HN Algolia: LangSmith 搜索结果页 - 持续聚合的多平台讨论
- 掘金搜索: LangSmith - 中文社区实践分享索引
- Reddit r/LangChain - 反爬未验证(HTTP 000)
对比基准
- Artificial Analysis 主页 - LLM 第三方评测;用于关联 LangSmith 观测的底层模型质量
- 量子位搜索 LangSmith - 反爬未验证(HTTP 403,body 无 404 关键词)
本文由 AI 生成。内容基于公开资料整理,可能存在事实偏差,引用链接请以原始来源为准。