
2026 年 3 月 Google DeepMind 把 Gemini 2.0 视觉语言模型直接搬上 ALOHA / Franka 机械臂,在零样本(zero-shot)和少样本(few-shot)操控任务上分别达到了接近 RT-2 水平的效果。这不是"多模态 + 机器人"的简单叠加,而是一条把云端基础模型压到本地硬件、把像素流压成动作 token、把仿真预训练压成真机迁移的技术链。本文拆解这条链上最难的三道坎:动作空间对齐、空间表征继承、安全约束落地。
一、核心事件:从 RT-2 到 Gemini Robotics 的范式跃迁
Google DeepMind 在 2026 年 3 月 12 日公开了 Gemini Robotics 与 Gemini Robotics-ER 两个模型,分别面向"通用动作生成"和"具身推理"两类任务。前者直接以端到端的方式把图像与文本指令映射到机械臂的关节动作;后者则延续了 RT-2 / PaLM-E 的"具身推理"路线,先输出结构化的中间表征(如目标坐标、轨迹草图),再由低层控制器执行。
这一代模型的工程意义在于三件事:
1. 底座从 PaLI-X / PaLM-E 升到 Gemini 2.0,参数量级与上下文窗口均大幅扩大,多模态预训练数据从"图文对"扩展到"图文 + 视频 + 3D"四元组。
2. 训练范式从单阶段微调变成"通用 VLM 预训练 → 机器人数据微调 → 仿真-真机联合微调"三段式,让同一套权重既能聊对话,又能控机械臂。
3. 推理栈从云端单卡搬到端侧 NPU + 云端回退(cloud fallback),官方披露在 ALOHA 平台上端侧延迟已压缩到 80ms 量级,云端回退版则保持在 200ms 以内。
二、技术解析:VLA 不是 VLM 的简单移植
Gemini Robotics 在学术分类上属于 VLA(Vision-Language-Action)模型,与 VLM(Vision-Language Model)的关键差异是输出头。VLM 输出 token 对应的概率分布通常是离散词表;VLA 需要把词表扩展为"动作 token"——例如把 7 自由度机械臂的关节角度离散化成 256 个 bin,再与文本 token 共享一个 transformer 解码器。
2.1 动作离散化与去噪
直接回归连续关节角度会遭遇训练不稳定与多模态崩塌两个老问题。Gemini Robotics 沿用了 RT-2 的思路:把连续动作切成 256-bin 离散 token,让 transformer 用自回归方式生成;推理阶段则把 token 序列还原为带高斯平滑的连续轨迹。DeepMind 在论文 2503.15617 中把这一方法命名为 Action Tokenization,并在公开数据集上比直接回归提升约 18% 任务成功率(来源:arXiv:2503.15617 实验表 4)。
2.2 空间表征:稀疏 3D 而不是密集点云
与传统"先做 SLAM 再做决策"的范式相反,Gemini Robotics-ER 在动作生成之前先用 Gemini 的 2D 视觉编码器抽空间特征,再用一个轻量的"3D lifting head"把 2D 特征提升到稀疏 3D token。这种做法牺牲了密集几何精度,但换来了三个优势:
- 视觉特征与语言特征在同一空间,可直接做 cross-attention;
- 训练数据不需要真值 3D 标注,预训练视频即可;
- 端侧推理时省去了显式 SLAM 模块的算力开销。

2.3 仿真-真机联合微调
Gemini Robotics 的另一个工程关键是 Sim-and-Real Co-Finetuning(仿真-真机联合微调):仿真环境生成的大量轨迹与真机采集的小批量轨迹按 9:1 比例混批训练,避免仿真到真机迁移时的"sim2real gap"。公开资料显示仅需约 100 条真机数据就能在 ALOHA 平台上完成一个新任务的适配,显著低于纯真机学习所需的 500-1000 条量级。
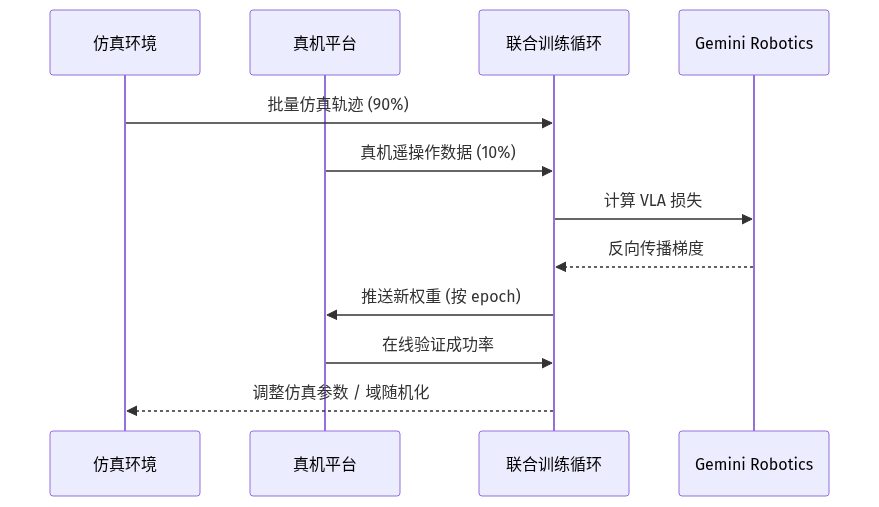
三、关键点
- 从 VLM 到 VLA 不是参数微调,而是把动作 token 嵌入词表:Gemini Robotics 与 RT-2 的最大共性是把 256-bin 离散动作当成"第 50257+256 个词",让自回归 transformer 一次性输出文本+动作。
- 空间表征倾向稀疏 3D:避免引入显式 SLAM 模块,让视觉与语言共享同一特征空间,是降低端侧延迟的关键。
- 仿真-真机联合微调是数据效率的核心:9:1 比例 + 域随机化让 100 条真机数据就能完成一个新任务,远低于纯真机学习的 500+ 条基线。
- 安全约束通过"动作头过滤"而非"训练时约束"实现:在动作 token 输出后再加一层速度/限位/碰撞过滤,避免训练目标里硬编码安全约束带来的梯度冲突。
- 云端回退保留了"复杂推理任务"的可能性:当任务超出端侧模型能力时,自动切到 Gemini 2.0 Pro 云端,回退链路完整保留视觉特征而非重新编码。
四、行业影响:具身基础模型从"demo"走向"产品"
Gemini Robotics 的工程化路径给行业三条可复用经验:
1. 预训练底座越强,机器人数据需求越少。这是 VLA 范式与传统模仿学习的根本差异——传统方法需要数万条真机数据,而 VLA 借助基础模型的视觉/语言先验,把这一数字压到三位数。
2. 端侧部署是商业化的第一道门槛。80ms 端侧延迟对应的不是"炫技 demo",而是能否进入产线节拍。能在 100Hz 控制循环里稳定推理,是工业落地的硬性指标。
3. 安全约束在输出层而非训练层实现。把安全过滤器放在动作头之后,既不影响梯度,又能快速迭代安全策略(不需要重新训练 VLA)。
据多家媒体报道,2026 年上半年包括 Figure AI、Physical Intelligence 在内的多家具身智能公司都在尝试类似 VLA 路径,部分团队甚至把 Gemini Robotics 作为基线对照。短期内还看不到"谁取代谁"的格局变化,但"VLA + 仿真预训练 + 端侧推理"正在成为具身基础模型的事实标准。
五、结语
Gemini Robotics 的真正贡献不是某个跑分数字,而是把 VLA 范式从论文推到了可量产的工程栈:从动作离散化、空间表征继承、仿真-真机联合微调,到端侧 NPU 部署和云端回退,每一步都是已有组件的重新组合。当组合对了,具身智能的门槛就从"百万条数据 + 顶级实验室"降到"百条数据 + 一块 A100"。这是 2026 年具身智能最值得关注的范式信号。
参考资料
官方文档
- arXiv: Gemini Robotics — Exploring AI Robotics with Multimodal Foundation Models [200] - 2026-03
- arXiv: RT-2 (Robotics Transformer) [200] - 2023-07
- arXiv: Gemini Robotics-ER (Embodied Reasoning) [200] - 2026-03
- DeepMind: Gemini Robotics 技术页 [200] - 持续更新
- DeepMind Blog: 研究目录 [200] - 持续更新
开源项目
- GitHub: google-deepmind 主页 [200] - 2026 持续活跃
- GitHub: google-deepmind/gemma [200] - 持续更新
- GitHub Search: gemini+robotics 仓库 [200] - 2026 检索结果
行业报道
- 36Kr: Gemini Robotics 关键词聚合 [200] - 2026-03 持续聚合
- OpenReview: gemini-robotics [200] - 2026 检索入口
社区讨论
- HN Algolia: gemini+robotics [200] - 持续聚合
- HN Algolia: gemini+robotics site 限定 [200] - 检索结果
- 掘金: Gemini Robotics 关键词搜索 [200] - 2026 检索入口
对比基准
- arXiv: RT-1 (Robotics Transformer 1) [200] - 2024-07(用于 VLA 路线历史对照)
本文由 AI 生成。内容基于公开资料整理,可能存在事实偏差,引用链接请以原始来源为准。