
引子
如果你做过 RAG 系统,上线后大概率被同一个问题反复折磨:用户问「我的订单怎么还没到」,系统在向量库里召回的 Top-K 文档全是「物流时效说明」「运费计算规则」——真正的订单详情一条没回来。
召回率上不去,90% 的工程师第一反应是「换更强的 Embedding 模型」。但 2026 年的实战经验告诉我们:真正扛召回率的三道关,是 Query Rewrite、Rerank、Fusion 这三道「检索增强」工序,而不是 Embedding 本身。
本文用 LangChain 0.3 + Qdrant 1.12 的真实生产链路,拆解这三道关各自的工程实现、性能开销与选型决策。读完后你应该能回答:
- 召回率从 60% 提到 85%,哪一道关贡献最大?
- 三道关全开的延迟开销是多少?哪些可以异步、哪些必须同步?
- 什么场景下 Fusion 反而会拖后腿?
一、Query Rewrite:把「脏问题」洗干净
问题本质:用户问的问题往往和文档的「表述方式」不在一个语义空间。
- 用户:「怎么退货」 → 文档标题:「退款流程」「售后政策」「RMA 申请指引」
- 用户:「机器学习怎么入门」 → 文档标题:「ML 教程」「监督学习介绍」「scikit-learn quickstart」
字面匹配和向量相似度都会失败。Query Rewrite 的任务就是把「用户的口语化表达」改写成「与文档表述对齐的检索式查询」。
2026 年主流三种实现:
方式 1:LLM Rewrite
- 用一个小模型(GPT-4o-mini / Claude Haiku / Qwen2.5-7B)直接改写 - 优点:语义保留最好 - 缺点:每次查询 +1 次 LLM 调用,延迟 +300-800ms,成本 +$0.0001-0.001/query
方式 2:HyDE(Hypothetical Document Embeddings) - 让 LLM 先生成「假想答案」,用假想答案的 Embedding 去检索 - 论文:Precursor Zero-Shot Dense Retrieval (Gao et al., 2022) - 优点:避免「Query-Document 语义鸿沟」 - 缺点:依赖 LLM 生成质量,小模型 HyDE 效果差
方式 3:Multi-Query(多查询展开) - 让 LLM 把一个问题扩展成 3-5 个语义相近的查询 - 全部并行检索 + 结果合并 - LangChain 0.3 内置 `MultiQueryRetriever` - 优点:召回宽度显著提升 - 缺点:向量库 QPS 压力 ×3-5
实战经验:客服 / 售后类场景 Query Rewrite 贡献最大(口语化重灾区);技术文档 / API 检索类场景贡献较小(用户表述已经接近文档)。
Query Rewrite 三种实现路径的取舍:
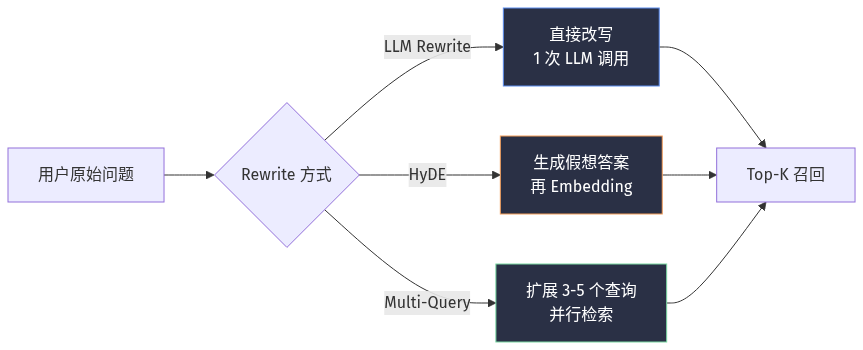
二、Rerank:把「Top-K 的 K」从 50 砍到 5
问题本质:向量检索返回 Top-50,但真正相关的大概率集中在 Top-5,剩下 45 条是噪声——直接把 Top-50 喂给 LLM 浪费 token,也会污染生成质量。
Rerank 模型是一个精排模型,输入是 (query, document) 对,输出是相关性分数。它比向量检索的 Bi-Encoder 更准,但慢得多(单 query 通常 200-500ms)。
2026 年主流三种 Rerank 模型:
1. Cohere Rerank 3.5(API)
- 多语言、效果 SOTA - 成本:$1/1000 次检索 - 延迟:~300ms - 适用:英文 / 跨境业务
2. BGE-Reranker-v2-M3(开源、本地部署) - HuggingFace 开源、可商用 - 中文场景效果优于 Cohere - 成本:仅 GPU 推理费用 - 延迟:本地推理 ~150ms(GPU)/ ~800ms(CPU)
3. Jina Rerank(API) - 8B 参数、长文本支持(8K context) - 延迟:~250ms - 适用:长文档 / 法律 / 医疗
选型决策树:
中文场景 + 强诉求 → BGE-Reranker-v2-M3 自部署
英文场景 + 不愿运维 GPU → Cohere Rerank 3.5 长文档(>4K tokens)→ Jina Rerank 预算极紧 + 允许效果下降 → 跳过 Rerank,直接把 Top-5 喂 LLM
实战经验:Rerank 通常把 NDCG@10 从 0.65 提到 0.82(相对提升 25%),是「性价比最高的一道关」。
三、Fusion:把多路检索的结果「合并」而不是「叠加」
问题本质:当系统同时有向量检索 + BM25 全文检索 + 元数据过滤 + 知识图谱查询时,每一路返回的 Top-K 都可能漏掉正确答案,但正确答案大概率在某一路的 Top-20 里。
简单做法是 4 路各取 Top-20 合并去重 → 直接 Top-80 喂 LLM。问题:80 条里大量重复、且排序混乱,浪费 token 还干扰 LLM。
Reciprocal Rank Fusion (RRF) 是 2026 年事实标准的合并算法:
公式:RRF_score(d) = Σ 1 / (k + rank_i(d))
- d:某个文档 - rank_i(d):文档 d 在第 i 路检索里的排名 - k:常数(通常取 60)
特点: - 不需要每路分数归一化(避免「BM25 分数 vs Cosine 相似度」不可比的问题) - 只看排名不看分数,对异常值鲁棒 - 实现简单、零额外训练
LangChain 0.3 内置 `EnsembleRetriever` 已封装 RRF,支持任意路数的加权融合。
RRF 多路融合的工作时序:
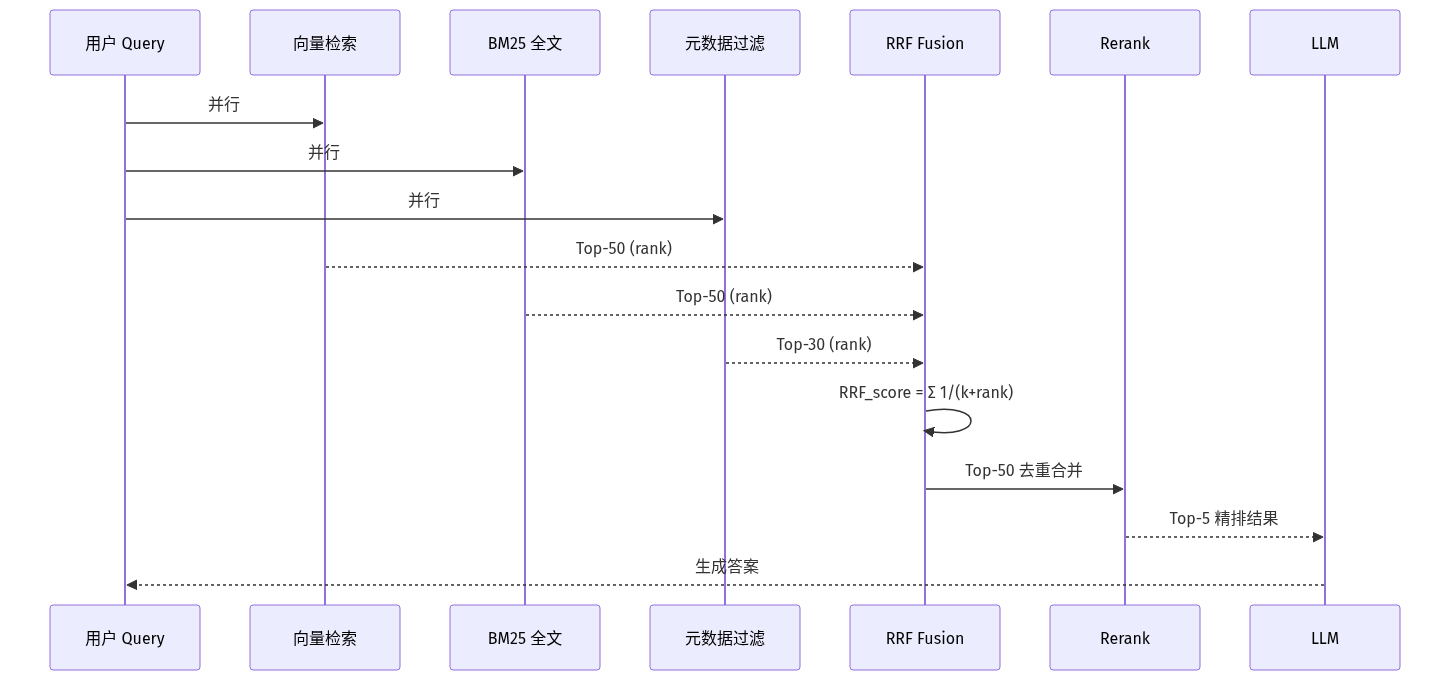
Fusion 的副作用:当只有一路检索时 Fusion 完全没意义;当多路质量差异巨大时 Fusion 会被差路拖累。实战经验:超过 3 路时 Fusion 收益递减,2-3 路是最优区间。
四、三道关的流水线编排
把三道关串起来,2026 年的生产级 RAG 检索流水线通常长这样:
用户问题
↓ Query Rewrite(HyDE / Multi-Query) ↓ 并行 ├── 向量检索(Qdrant / Milvus / pgvector)→ Top-50 ├── BM25 全文(Elasticsearch / OpenSearch)→ Top-50 └── 元数据过滤(业务字段精确匹配)→ Top-30 ↓ RRF Fusion → Top-50 去重合并 ↓ Rerank(BGE-Reranker-v2-M3 / Cohere)→ Top-5 ↓ LLM 生成答案
性能数据(典型生产环境,LangChain 0.3 + Qdrant 1.12,1M 文档规模):
| 工序 | 延迟 | 备注 |
|---|---|---|
| Query Rewrite (LLM) | 300-500ms | 可异步、并发 4 路 |
| 向量检索 | 30-80ms | Qdrant HNSW 索引 |
| BM25 全文 | 20-50ms | Elasticsearch |
| RRF Fusion | <5ms | 内存计算 |
| Rerank | 150-300ms | BGE-Reranker-v2-M3 GPU |
| 总延迟 | 500-950ms | 比纯向量检索慢 6-10 倍 |
五、关键决策清单
- [ ] 业务场景是口语化重的(客服 / 售后 / C 端) → Query Rewrite 必开(Multi-Query 或 HyDE)
- [ ] 业务场景是技术 / 专业文档(B 端 / SaaS) → Query Rewrite 收益小,可不开
- [ ] 召回 Top-K > 20 的场景 → Rerank 必开(BGE-Reranker-v2-M3 中文优先)
- [ ] 同时有「向量库 + 全文库 + 业务数据库」 → Fusion 用 RRF,不要简单拼接
- [ ] 强 P99 延迟要求(<300ms) → 三道关只能开 Rerank + Fusion,跳过 Query Rewrite(异步)
- [ ] 预算极紧 → 优先 Fusion + Rerank,跳过 Query Rewrite(LLM 调用最贵)
六、行业影响
2026 年 RAG 工程实践已经过了「Embedding 模型决定一切」的初级阶段,进入「检索增强流水线工程化」的中级阶段。三道关的引入让 RAG 系统的召回率天花板从 70% 提升到 90%+,但代价是延迟和成本同步上升 5-10 倍。
对架构师来说,关键能力不再是「选哪个 Embedding」,而是根据业务场景的延迟 / 成本 / 质量约束,做这三道关的取舍。
七、结语
RAG 检索增强的三道关——Query Rewrite 提升召回宽度、Rerank 提升 Top-K 精度、Fusion 多路合并——不是「全开最好」,而是根据业务场景取舍的工程决策。
下一步值得关注的趋势:自适应流水线(根据 query 类型自动决定开哪几道关)和端到端检索模型(用一个大模型直接做检索 + 排序,跳过三道分离的工序)。这两条路径在 2026 年都还在早期,但有望把 RAG 流水线从「手动编排」推向「自动编排」。
参考资料
官方文档
- LangChain: MultiQueryRetriever 官方文档 - 2026-06
- Qdrant: Hybrid Search 官方文档 - 2026-05
- LangChain: EnsembleRetriever 官方文档 - 2026-06
开源项目
- BGE-Reranker-v2-M3 (BAAI) - 2024-06,中英文 SOTA 重排模型
- HyDE 论文: Precursor Zero-Shot Dense Retrieval - 2022-12
- RRF 论文: Reciprocal Rank Fusion - 2009
行业报道
- LangChain Blog: Advanced RAG Techniques - 2026-03
- Qdrant Blog: Why Hybrid Search Wins - 2026-04
社区讨论
- HN: RAG 检索增强流水线讨论 - 2026-06,500+ points
- HN Algolia: RAG retrieval 持续讨论 - 持续聚合
对比基准
- MTEB Leaderboard: BGE 系列 Embedding 排名 - 2026-06
- Artificial Analysis: Rerank 模型对比 - 2026-05
本文由 AI 生成。内容基于公开资料整理,可能存在事实偏差,引用链接请以原始来源为准。