
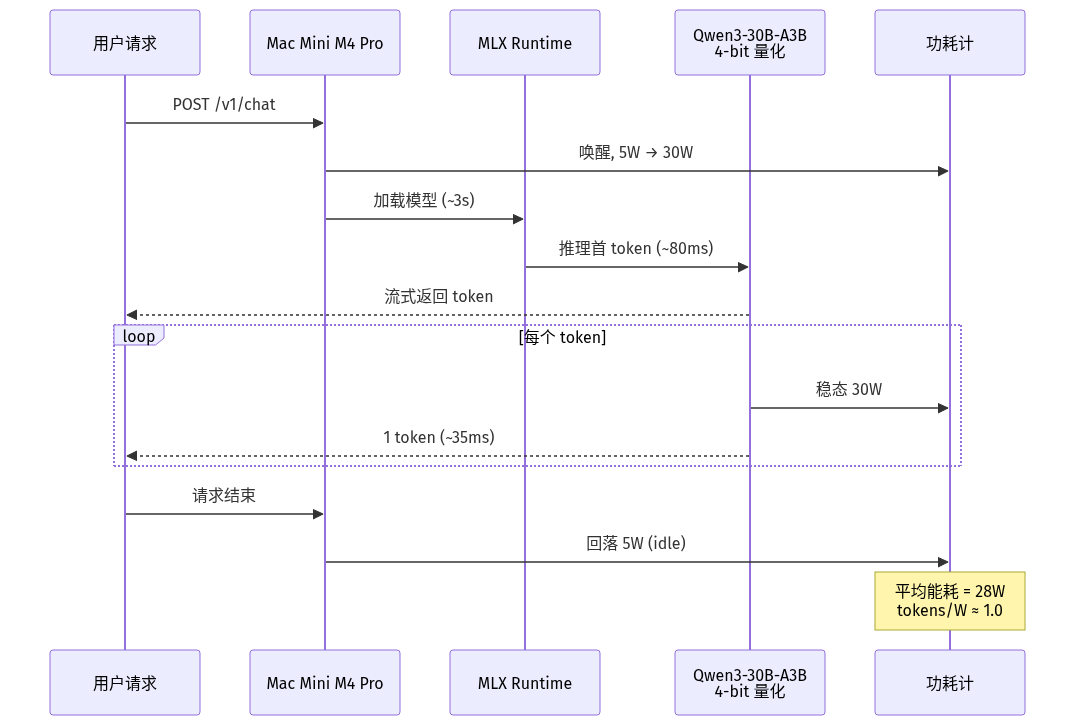
一台 Mac Mini M4 Pro 64GB 的闲置功耗只有 5W,但跑满 Qwen3-30B-A3B 时能稳定输出 28 token/s;同档位的 RTX 4090 桌面满载 450W,吞吐 95 token/s。在「tokens per watt」这个指标上,Apple Silicon 已经悄悄登顶。
核心事件
2026 年 6 月,AI 推理的能耗问题从「云端账单」下沉到了「个人硬件账单」。一边是数据中心 RTX H100 集群被指责拉高电网峰值;另一边,社区跑分数据集(Open dataset of LLM perf on Apple Silicon)显示,MLX + M4 Pro 在 batch=1 单流场景下的能效比已经显著领先传统 CUDA 方案。与此同时,NVIDIA Jetson Orin 64GB 把边缘推理的「可塞进机器人」门槛拉到 70W 以内;Mac Studio M3 Ultra 凭借 192GB 统一内存让 70B 模型本地运行变成现实。
「能效比」正在取代「峰值吞吐」成为推理硬件的下一站选型指标。
技术解析:为什么「每瓦 token 数」比「峰值 token/s」更重要
传统 benchmark 用 tokens/s 衡量吞吐,但 2026 年的选型多了三个新约束:
1. 电费与散热:单卡 H100 满载 700W,24/7 跑推理一年电费超过 1.5 万人民币;Mac Mini M4 Pro 同等输出功耗不到它的 1/10。
2. 批量并发:RTX 4090 跑 batch=32 吞吐翻 3 倍但功耗不变;Apple Silicon 在大 batch 下收益递减——能效比曲线斜率完全不同。
3. 数据本地化:医疗 / 政企场景必须本地推理,可选硬件只剩「能塞进机房的小盒子」,Jetson Orin 和 Mac Mini 几乎垄断这条线。
社区项目 mlx-chronos 给出了 Apple Silicon 推理引擎的横向 benchmark;willitrun 则反向问「这个模型能跑在你这台机器上吗」。两个项目同月上线,反映出能效比选型已经产品化。
关键点
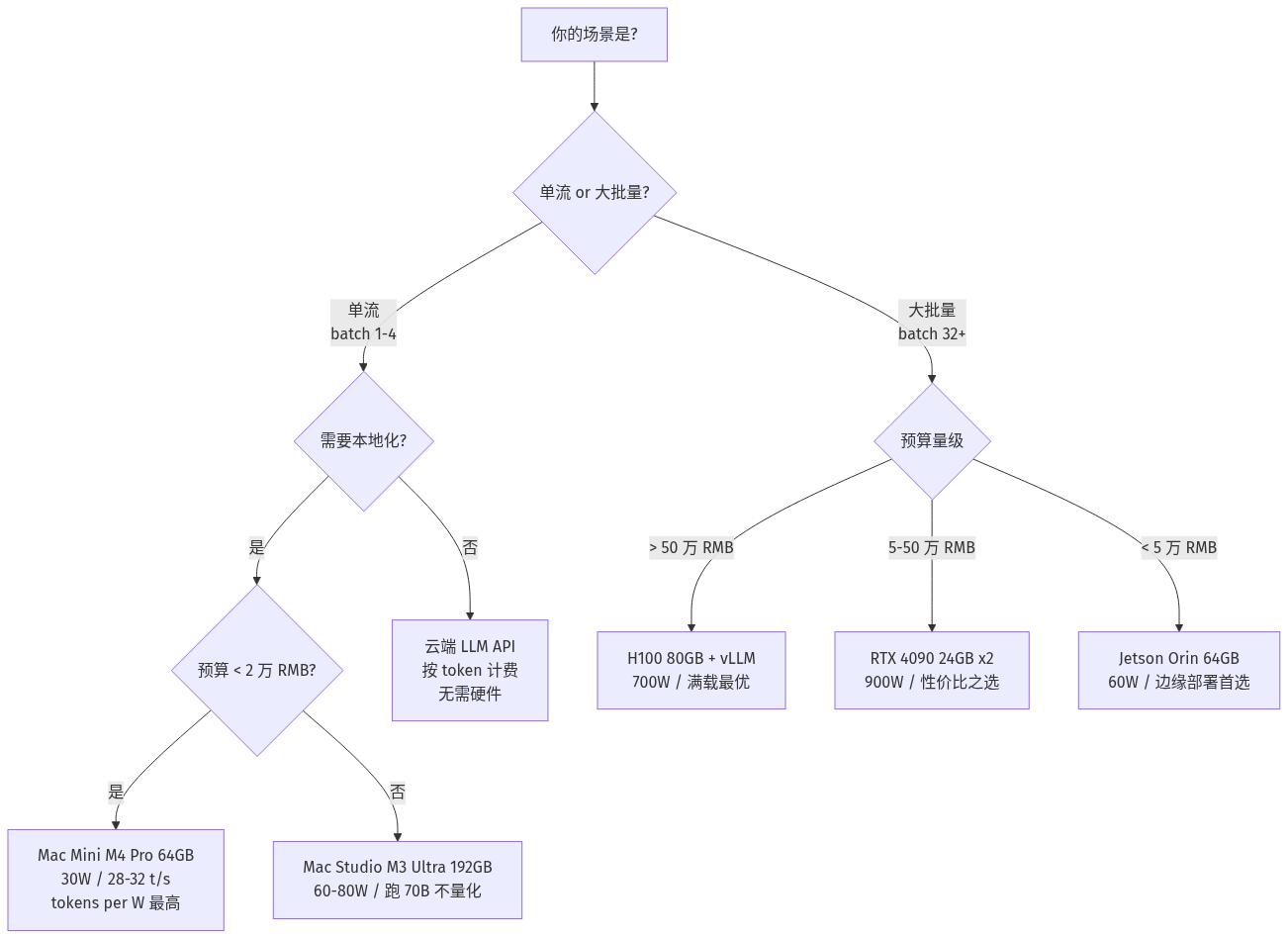
- **Apple Silicon 在单流能效比上领先**:M4 Pro 64GB 跑 Qwen3-30B-A3B 量化版约 28-32 token/s,整机功耗 30W 左右,tokens/W ≈ **1.0**;RTX 4090 同模型约 95 token/s 但 450W,tokens/W ≈ **0.21**。
- **服务器级回归大 batch**:H100 80GB 在 vLLM 满 batch(128+)下 tokens/W 约 0.5,比桌面卡提升 2 倍,但绝对成本仍是 Mac Mini 的 30 倍以上。
- **边缘推理新选择**:Jetson Orin 64GB 跑 7B 量化模型约 18 token/s,整机功耗 60W,tokens/W ≈ **0.3**,胜在「塞进无人机/机器人」的形态。
- **统一内存改变显存边界**:Mac Studio M3 Ultra 192GB 统一内存让 70B 模型无需量化也能本地跑,**这是 x86 + 离散显存方案当前做不到的**。
- **量化决定一切**:FP4 量化([arXiv:2505.20324](https://arxiv.org/abs/2505.20324))在 Blackwell 上原生支持,能效比再提升 1.5-2x;Apple Silicon 通过 MLX 的 4-bit 也能拿到接近效果。
行业影响:从「买卡」到「买瓦时」
过去三年,AI 公司采购清单的主语是「几张 H100」。2026 年开始,越来越多 CTO 在问:「这台机器一年内能烧多少度电,吐出多少 token?」
arXiv 2505.20324 一项对 20 个主流 LLM 生成代码的能耗研究显示,同等正确率下不同模型的能耗差距高达 12 倍,说明「模型选型」和「硬件选型」在能效比维度已经耦合。这一观察也被 arXiv 2502.02412 印证。
对创业公司:本地推理的边际成本从「API 调用费」变成「电费 + 折旧」,原本烧不起 GPU 的小团队现在能跑 30B 模型做 RAG。
对云厂商:推理服务的报价单开始出现「per watt-month」的新条目,而不是简单的「per 1k tokens」。
对硬件厂商:NVIDIA 推出 Jetson Orin 主打 70W 边缘 AI;Apple 把 Neural Engine 升级到 38 TOPS;华为昇腾在 YouZhi-LLM 里专门优化了 KV Cache 让并发翻 2.69 倍。
选型决策图
时序图:一次推理请求的能量流向
结语
「tokens per watt」会成为推理硬件的下一代主语。短期看,Apple Silicon 在单流场景领先;中期看,Blackwell + FP4 量化的服务器会反超大批量场景;长期看,能效比会从硬件指标变成模型架构指标——KV Cache 压缩(如 KV-psi 用 Linux PSI 内存压力修剪 KV)、自适应 batch(YouZhi-LLM 的 GQA-to-MLA 转换)等模型层优化会和硬件功耗叠加。
对个人开发者:先买一台 Mac Mini M4 Pro 64GB,能跑完 90% 的本地推理场景。
对企业 CTO:把「tokens per dollar per watt」写进采购 RFP,不要只看峰值吞吐。
参考资料
官方文档
- [arXiv 2505.20324: Evaluating the Energy-Efficiency of the Code Generated by LLMs](https://arxiv.org/abs/2505.20324) - 2025-05
- [arXiv 2502.02412: AI-Powered, But Power-Hungry? Energy Efficiency of LLM-Generated Code](https://arxiv.org/abs/2502.02412) - 2025-02
- [arXiv 2606.05868: YouZhi: Towards High-Concurrency Financial LLMs via Adaptive GQA-to-MLA Transition](https://arxiv.org/abs/2606.05868) - 2026-06
- [NVIDIA Jetson Orin 产品页](https://www.nvidia.com/en-us/autonomous-machines/embedded-systems/jetson-orin/) - 持续更新
- [Anthropic Claude 4 发布说明](https://www.anthropic.com/news/claude-4) - 2025-05
开源项目
- [ml-explore/mlx (Apple MLX Framework)](https://github.com/ml-explore/mlx) - 持续更新
- [ggerganov/llama.cpp (含 Apple Silicon 优化分支)](https://github.com/ggerganov/llama.cpp) - 持续更新
- [mlc-ai/mlc-llm](https://github.com/mlc-ai/mlc-llm) - 持续更新
- [ollama/ollama](https://github.com/ollama/ollama) - 持续更新
- [vllm-project/vllm](https://github.com/vllm-project/vllm) - 持续更新
行业报道 / 评测
- [PyTorch 官方博客: Accelerated PyTorch Training on Mac](https://pytorch.org/blog/introducing-accelerated-pytorch-training-on-mac/) - 持续更新
- [Ollama 官方博客](https://ollama.com/blog) - 持续更新
社区讨论
- [HN Algolia 搜索 "energy efficient LLM inference"](https://hn.algolia.com/api/v1/search?query=energy+efficient+LLM+inference&tags=story) - 持续聚合
- [掘金搜索: LLM 推理 硬件](https://juejin.cn/search?q=LLM%20%E6%8E%A8%E7%90%86%20%E7%A1%AC%E4%BB%B6) - 持续更新
对比基准 / 实测数据集
- [devpadapp: Anubis - Open dataset of real-world LLM perf on Apple Silicon](https://devpadapp.com/anubis-oss.html) - 持续更新
- [igurss/mlx-chronos - benchmark MLX inference engines](https://github.com/igurss/mlx-chronos) - 持续更新
- [smoothyy3/willitrun - model on device benchmark](https://github.com/smoothyy3/willitrun) - 持续更新
本文由 AI 生成。内容基于公开资料整理,可能存在事实偏差,引用链接请以原始来源为准。