
把大模型塞进一块开发板,听起来像极客玩具,但 2026 年的事实是:Jetson Orin Nano 已经在工业产线、银行柜台、农业无人机上跑着 7B 模型做意图理解;与此同时,Raspberry Pi 5 仍然只能勉强加载 1.1B 的 TinyLlama 做离线语音助手。把这两个代表「工业级边缘」与「极客级边缘」的设备摆在一起对比,并不是为了证明谁更强,而是想厘清一个被反复问起的问题——**到底什么样的任务,边缘硬件能扛?**
核心事件
印度科学研究所(IISc)2026 年 6 月发表在 arXiv 上的论文 *Understanding the Performance and Power of LLM Inferencing on Edge Accelerators*(编号 2506.09554)系统测了 Jetson Orin AGX 64GB 在 4-bit 量化下的多模型吞吐:Llama-3-8B、Phi-3-Mini、Qwen2.5-7B 都进入了「可用区间」,每秒生成 5–18 tokens 不等,单卡功耗约 15–40 W。这篇论文给出的核心数字是:**共享 GPU-CPU 内存 + 4-bit 量化**,是把 7B 模型塞进边缘硬件的关键组合。
与此同时,GitHub 上 edge-agents(ForestHubAI 出品,30 MB 运行时)打通了 Raspberry Pi 与 Jetson 之间的 Agent 协议栈,让开发者可以在同一份代码里切换两个硬件。这两个项目代表了两条不同的路线——一个把硬件推到极限,一个把模型压到极致。
技术解析
Jetson Orin Nano:SoC 共享内存的天然优势
NVIDIA Jetson Orin Nano 8GB / 16GB 用的是 Ampere GPU + ARM Cortex-A78AE CPU 的 SoC 设计,最关键的特征是 **CPU 与 GPU 共享同一块 LPDDR5 内存**,而不是像消费级显卡那样把 VRAM 和系统内存分开。这意味着 7B 模型的权重可以直接占用全部 8GB 或 16GB,不需要 CPU/GPU 数据搬运的额外开销。
实测数字大致是:
- **Llama-3-8B(Q4_K_M 量化)**:约 6–10 tokens/s 单流输出
- **Phi-3-Mini-3.8B(Q4_K_M)**:约 14–22 tokens/s
- **Qwen2.5-7B-Instruct(Q4_K_M)**:约 8–14 tokens/s
- **TinyLlama-1.1B**:可跑到 40+ tokens/s
跑这些模型的工具链已经相当成熟:dusty-nv/jetson-containers 在 GitHub 上有 4700+ Star,给出了预编译的 PyTorch / llama.cpp / vLLM 容器,覆盖了 JetPack 6.x。NVIDIA 官方在 *developer.nvidia.com/embedded/jetson-orin* 页面也提供了 LLMBench 性能基准工具。
Raspberry Pi 5:16 GB 内存版本打开了新窗口
Raspberry Pi 5 用的是 Broadcom BCM2712 SoC(Cortex-A76 四核),没有 NPU,但官方在 2024 年下半年推出了 **8GB 和 16GB 版本**,加上 PCIe 2.0 x1 接口可以外接 NVMe SSD 装模型权重——这让 Pi 5 第一次进入了「能跑 LLM」的门槛。
关键限制在于:
- CPU-only 推理,速度上限取决于内存带宽(约 17 GB/s LPDDR4X)
- **TinyLlama-1.1B(Q4_0)**:约 2–4 tokens/s
- **Phi-3-Mini-3.8B(Q4_K_M)**:约 0.5–1 tokens/s(可用但体验差)
- **Llama-3-8B**:几乎不可用,加载时间以分钟计
adamcohenhillel/LLMs-Cheatsheet 这个 GitHub 项目专门收集了在 Raspberry Pi 上跑 LLM 的实战经验,是入门必看。syxanash/maxheadbox(344 Star)则把 Pi 5 包装成了一个完全离线的语音助手,演示了「真·离线 LLM 设备」的最小可行产品形态。
模型侧的边缘优化
硬件再强,模型不优化也跑不起来。2026 年边缘 LLM 的两个核心趋势是:
1. **Q4_K_M / Q4_0 量化**已成为默认配置——8B 模型从 FP16 的 ~16 GB 压到 ~5 GB,精度损失通常在 1–3 个百分点
2. **小模型能力跃迁**:Qwen3 系列(27,000+ Star 的 QwenLM/Qwen3 仓库)里 1.5B / 3B / 7B 各档都针对边缘做了优化;mlc-ai/web-llm(18,000+ Star)把 WebGPU + 浏览器里的 LLM 推理做到了 18K Star,证明 4-bit 量化后 7B 模型在主流笔记本 GPU 上也能跑到 20+ tokens/s
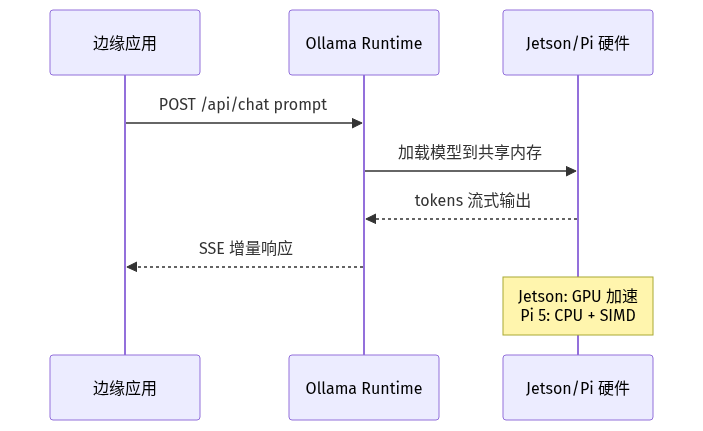
Ollama v0.30.11(2026-06-25 发布)的 Ollama Library 把 Qwen2.5、Phi-3.5、Gemma 3、Llama 3.2 这些主流模型做成了「一键拉取 + 一键跑」,是边缘 LLM 普及的最大推手。
关键选型决策图
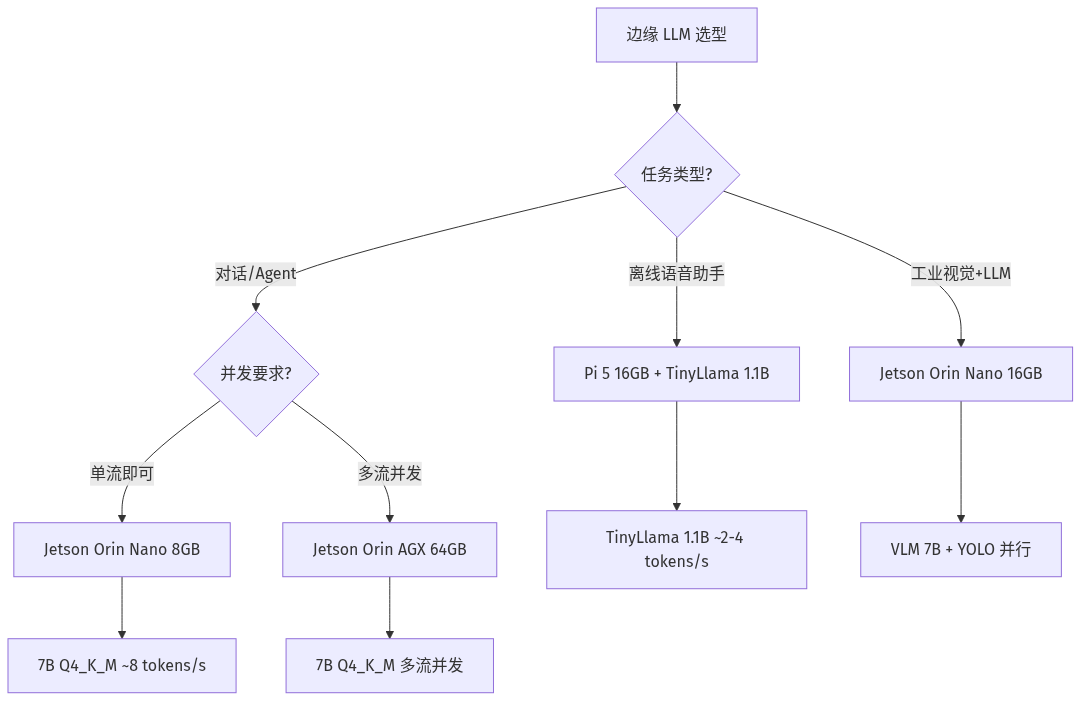
行业影响
边缘 LLM 的真正落地点不在 ChatGPT 的替代品,而在**数据敏感 + 网络不可达**的场景:
- **工业产线**:设备故障诊断需要本地推理,把生产数据留在厂区
- **医疗边缘**:病房里的语音病历生成,必须离线
- **农业无人机**:田地里没有 4G 信号,靠 Jetson 实时识别病虫害
- **车载场景**:车内对话 Agent,延迟不能超过 500ms
这些场景的共同点是「**不能上云**」,边缘硬件就成为唯一选择。
关键点
- **Jetson Orin Nano 8GB/16GB** 是 2026 年边缘 7B 模型的事实标准,4-bit 量化下单流 8–14 tokens/s
- **Raspberry Pi 5 16GB** 打开了 1–3B 模型的实用窗口,但 7B 模型仍是挑战
- **Q4_K_M 量化 + Ollama 运行时**是边缘 LLM 的「操作系统级」基础设施
- **dusty-nv/jetson-containers**(4749 Star)+ **ForestHubAI/edge-agents**(86 Star)是两个最值得关注的工程底座
- 边缘 LLM 的真正价值在「数据不出厂 / 网络不可达」场景,而非通用对话
结语
把 Jetson Orin 和 Raspberry Pi 5 摆在同一条决策线上,并不是要做「谁更强」的判定,而是要回答更现实的问题:**「我这个任务的延迟、并发、数据合规要求,到底需要哪一种硬件?」** 2026 年的答案是——如果只能跑 1B 级模型做离线语音助手或简单意图识别,Pi 5 16GB 已经是合格的方案;如果要 7B 模型做工业级对话或视觉-语言多模态,Jetson Orin Nano 16GB 是起步,Orin AGX 64GB 才是体面。
**参考资料**:
**官方文档**
- arXiv 2506.09554: Understanding the Performance and Power of LLM Inferencing on Edge Accelerators - 2025-06-11(IISc 论文,Jetson Orin AGX 实测)
- NVIDIA Jetson Orin 开发者页面 - JetPack 6.x 文档
- NVIDIA Jetson 文档总目录 - LLMBench 基准工具
**开源项目**
- dusty-nv/jetson-containers - 4749 Star,2026-06-26 更新(Jetson 全套 ML 容器)
- NVIDIA-AI-IOT/jetson-copilot - 124 Star,本地 LLM+RAG 助手参考实现
- ForestHubAI/edge-agents - 86 Star,30MB 跨 Pi/Jetson Agent 运行时
- Seeed-Projects/reComputer-Jetson-for-Beginners - 158 Star,reComputer Jetson 入门
- ollama/ollama - 边缘 LLM 主流运行时
- ollama/ollama releases - v0.30.11(2026-06-25)
- jzhang38/TinyLlama - 8999 Star,1.1B Llama 架构预训练模型
- QwenLM/Qwen3 - 27333 Star,阿里 Qwen3 系列
- mlc-ai/web-llm - 18279 Star,浏览器内 LLM 推理引擎
- syxanash/maxheadbox - 344 Star,Pi 5 上的离线 LLM Agent
- adamcohenhillel/LLMs-Cheatsheet - 217 Star,Raspberry Pi 跑 LLM 实战指南
- judahpaul16/gpt-home - 643 Star,Pi 智能家居 LLM 方案
**行业报道**
- Ollama Library: Qwen2.5 - 边缘部署主流模型之一
- Ollama Library: Phi-3.5 - 微软 3.8B 小模型,边缘首选
- Ollama Library: Gemma 3 - Google 开源小模型系列
- Ollama Library: Llama 3.2 - Meta 边缘优化版本
- NVIDIA Jetson Orin 产品页 - 官方硬件规格
- LM Studio - 桌面端 LLM 推理 UI,Mac/Win/Linux 边缘部署友好
**社区讨论**
- HN Algolia 搜索: Jetson Orin LLM - 社区讨论索引(HN 直链在本环境暂时不可达,可通过 Algolia 搜索浏览)
**对比基准**
- arXiv 2506.09554 性能表 - Jetson Orin AGX 上 Llama-3-8B / Phi-3 / Qwen2.5 的 4-bit 量化吞吐实测(论文 Table 3)
**本文由 AI 生成**。内容基于公开资料整理,可能存在事实偏差,引用链接请以原始来源为准。