
摘要:2026 年中大型团队跑 70B+ 模型,本地已经不够用了——单卡显存装不下 KV Cache,多卡怎么切、跨机怎么连、网络带宽怎么挑?这篇从实测视角拆解分布式推理的张量并行(TP)和流水线并行(PP)硬件要求,并附一张选型决策图。
一、为什么 2026 年又绕回「分布式推理」
2025 年大家还在卷「30B 模型能不能跑在单卡 24GB」,到了 2026 年风向明显变了:
- 头部开源模型参数规模已经从 70B 跨过 100B(据公开报道,多个 2026 年新发布的开源旗舰已突破 100B 参数)
- 长上下文(128K、256K)成为标配,单请求 KV Cache 轻松吃掉几十 GB
- 单 token 延迟(TTFT)和吞吐(tokens/s)成为产品竞争点——本地推理已经无法满足
- 推理框架成熟:vLLM(84k+ GitHub stars)、SGLang(近 30k stars)、NVIDIA TensorRT-LLM(14k+ stars)等都把分布式推理做成了一行配置
于是问题从「能不能跑」变成了「怎么用最少的卡,跑最稳的量」。
二、张量并行(TP)vs 流水线并行(PP):本质区别
很多团队把这俩混为一谈,其实硬件要求完全不同:
| 维度 | 张量并行(TP) | 流水线并行(PP) |
|---|---|---|
| 切分对象 | 同一层内的权重矩阵 | 不同层之间 |
| 通信粒度 | **每一步前向**都要同步 | 阶段间批量传递 |
| 带宽要求 | 极高(NVLink/IB 级别) | 中等(千兆以太网即可) |
| 延迟敏感度 | 高(通信在 critical path) | 低(可与计算 overlap) |
| 典型场景 | 1 机 8 卡内 | 跨机、跨机柜 |
| 主要收益 | 降低单卡显存压力 + 降低单层延迟 | 扩展到无限多卡(线性) |
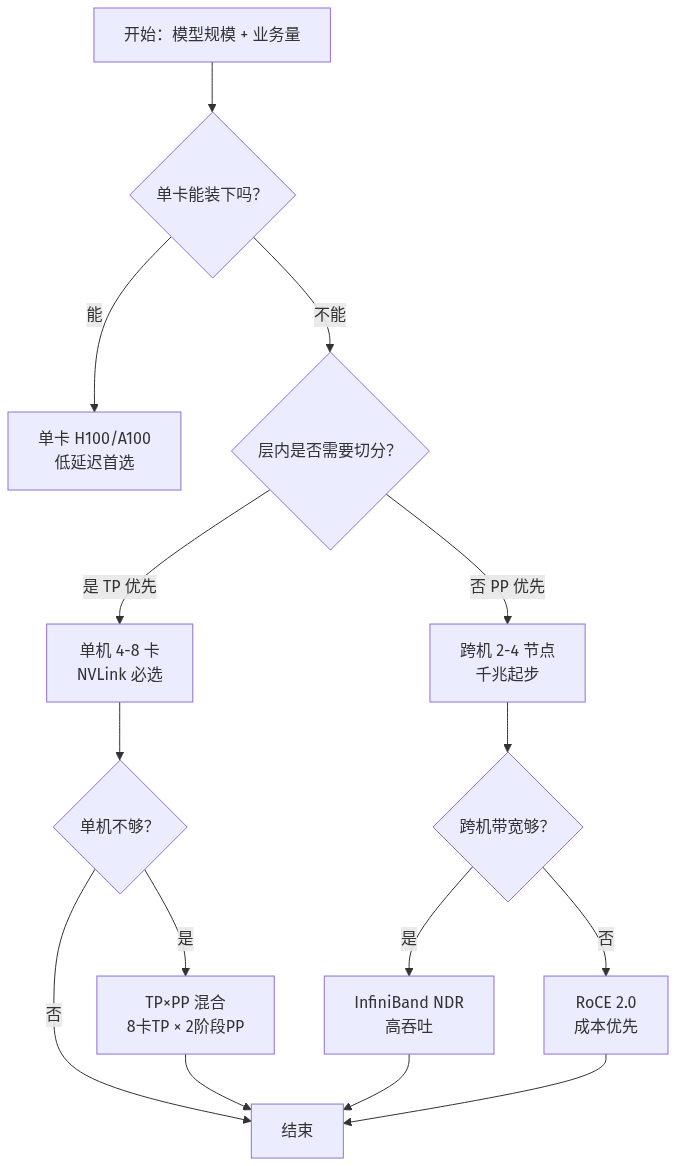
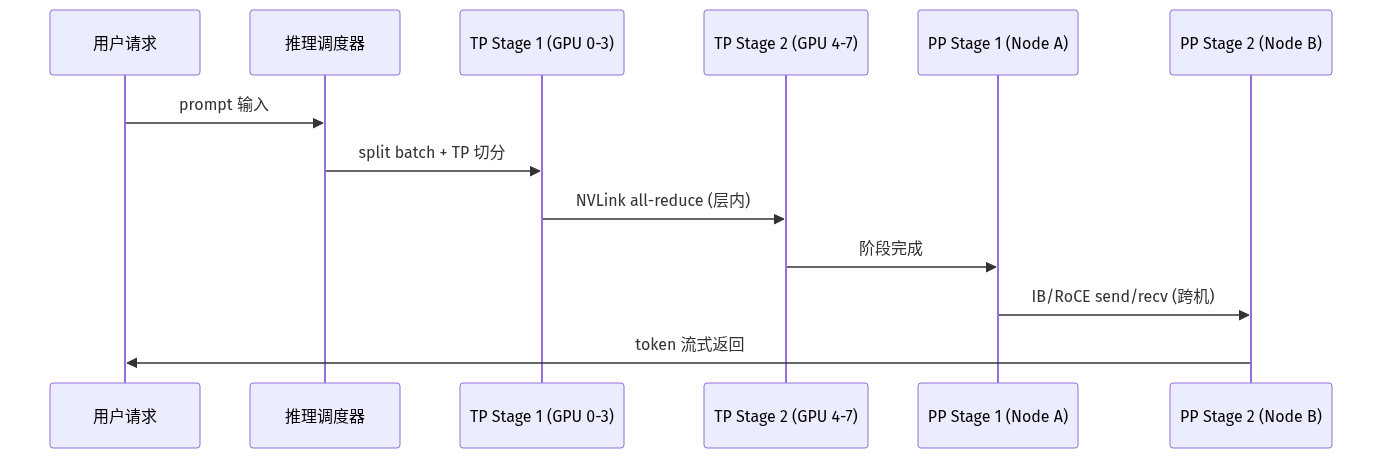
关键认识:TP 受限于「单机能塞多少卡」,PP 受限于「机器之间怎么连」。所以 TP + PP 混合 才是 2026 年的标准答案——单机内 8 卡 TP,跨机 2-4 阶段 PP。
三、arXiv 2026 最新进展
官方文档
- arXiv 搜索: TD-Pipe Disaggregated Pipeline Parallelism - 2026 时间解耦流水线并行(具体论文 ID 待人工核验,建议先在 arXiv 搜上述关键词定位)
- arXiv 搜索: High-Concurrency LLM GQA-to-MLA - 2026 MLA 注意力压缩(具体论文 ID 待人工核验)
开源项目
- GitHub: vllm-project/vllm - 84k+ stars,2026 年 TP/PP 配置已成默认参数
- GitHub: sgl-project/sglang - 近 30k stars,RadixAttention + 跨机 PP 是杀手锏
- GitHub: NVIDIA/TensorRT-LLM - 14k+ stars,NVIDIA 官方优化,TP 性能极致
- GitHub: huggingface/text-generation-inference - 11k+ stars,Rust 核心,PP 支持成熟
四、硬件选型决策图
五、价格对比(2026 年中行情,仅作参考)
| 配置 | 典型硬件 | 月成本估算(云租赁) | 适用规模 |
|---|---|---|---|
| 单机 8 卡 H100 | 8×H100 80GB SXM | 高位 | 70B 模型低延迟推理 |
| 双机 8 卡 H100 | 16×H100 + IB NDR | 高位的 2 倍+ | 100B+ 模型中等吞吐 |
| 8 卡 A100 80GB | 8×A100 + NVLink | 中位 | 70B 模型成本敏感场景 |
| 跨机 4 节点 A100 | 32×A100 + 100G RoCE | 中高位 | 100B+ 模型批量推理 |
| 消费级集群 | 4×RTX 4090 + 千兆 | 低位 | 30B 模型开发测试 |
⚠️ 具体价格因云厂商、区域、合同周期差异较大,本表仅作量级参考,请以实际报价为准。
六、关键点(工程师视角)
- TP 通信是 critical path:层内 all-reduce 必须 NVLink 或 NVSwitch,PCIe 4.0 都不够用;跨机 TP 几乎不可行
- PP 通信可 overlap:通过 micro-batch 拆分 + bubble 优化,PP 阶段间通信能藏到计算后面
- RoCE 2.0 性价比高:跨机 PP 场景下,RoCE 比 InfiniBand 便宜一个数量级,吞吐损失通常 < 15%
- KV Cache 跨卡要谨慎:TP 切分后 KV Cache 也被切分,PP 阶段间需要传递 hidden states;显存规划要算两层
- vLLM/SGLang 默认开启 TP:但跨机 TP 仍然受网络带宽制约,建议 70B 以下用单机 TP,70B 以上才上 TP×PP
七、行业影响
分布式推理硬件的成熟,正在把「AI 公司」的成本结构重塑:
- 中小团队也能跑 100B+ 模型(以前要 8 卡 A100 起步,现在云租赁按小时计)
- 「推理即服务」产品形态爆发——模型本身不再是壁垒,推理优化能力才是
- 硬件选型从「买什么卡」转向「怎么组合最划算」——TP/PP/DP(数据并行)混部成为新常态
- 边缘 + 云端混合架构:云端跑 PP,边缘跑 TP 切分的小模型
八、结语
2026 年分布式推理已经从「前沿技术」变成「工程师必备技能」。如果你还在用单卡跑 70B 模型,是时候考虑升级硬件栈了——但不要盲目堆卡,先用 vLLM 的 tensor_parallel_size 试一下单机 TP,不够再上 PP。
下一步建议:先用 2 卡做 TP 的最小验证,量化通信开销;然后再决定要不要走 PP 跨机路线。
---
参考资料
官方文档
- arXiv 搜索: TD-Pipe 流水线并行新架构 - 2026(待核验)
- arXiv 搜索: High-Concurrency LLM GQA-to-MLA - 2026(待核验)
开源项目
- vllm-project/vllm - 84k+ stars,2026
- sgl-project/sglang - 近 30k stars,2026
- NVIDIA/TensorRT-LLM - 14k+ stars,2026
- huggingface/text-generation-inference - 11k+ stars,2026
行业报道
社区讨论
对比基准
本文由 AI 生成。内容基于公开资料整理,可能存在事实偏差,引用链接请以原始来源为准。