
导语:当大模型不再只是「问答医生」,而是走进诊室做「第二意见」,2026 年的临床辅助决策(CDSS)正从论文走向开源项目与真实部署。这一年里,arXiv 上关于 LLM 介入临床决策的研究密集出现,GitHub 上多个面向单一病种的 CDSS 项目获得可观关注;与此同时,FDA 对「软件即医疗器械」(SaMD)的监管框架与 HIPAA 的隐私边界,决定了这些系统能否真正进入临床。
核心事件:LLM-CDSS 从论文走向开源
2026 年 6 月,arXiv 在过去三周内连续刊出多篇与 LLM 临床决策支持直接相关的研究:
- 6 月 15 日,《Medical Heuristic Learning: An LLM-Driven Framework for Interpretable and Auditable Clinical Predictions》提出了一种「启发式学习」框架,让大模型在保留可解释性的同时输出可审计的临床预测。
- 6 月 12 日,《Trust but Verify: Mitigating Medical Hallucinations via Post-Hoc Adversarial Auditing》聚焦医疗幻觉问题,用对抗性审计后置纠错来降低 LLM 误诊风险。
- 6 月 17 日,《Language Models as Interfaces, Not Oracles: A Hybrid LLM-ML System for Pediatric Triage》明确把 LLM 定位为「接口」而非「神谕」——儿科分诊场景下与 ML 模型混合使用。
这些论文背后的工程化产物已经在 GitHub 上可见:5 月 16 日更新的 multi-agent CDSS 项目把「可解释对话 + 患者友好沟通」作为核心能力;同日段更新的 SafeMeds 前端专注于「药物-药物相互作用」自然语言查询;5 月 5 日更新的 RAG 医疗聊天机器人则给出了 FastAPI + LangChain + Pinecone 的全栈模板。
技术解析:单 Agent、RAG 与多 Agent 的三种路径
医疗 CDSS 的 2026 年实现,大致可归为三类技术栈:
路径一:单 Agent + 知识库(RAG)。把临床指南、药品说明书、医院 SOP 灌入向量库,由 LLM 检索增强后回答医生查询。代表项目是上文提到的 RAG 医疗聊天机器人(Apache-2.0 协议),优势是搭建快、可解释性靠检索结果兜底;劣势是单轮决策质量受检索召回率制约。
路径二:多 Agent 协同。把「病史采集」「鉴别诊断」「检查建议」「医患沟通」拆给不同 Agent,例如 multi-agent-clinical-decision-support-system 项目把 explainable dialogue 列为头号特性。它的好处是单一 Agent 的失败不会拖垮全流程,坏处是 Agent 间的一致性需要专门测试。
路径三:LLM 作为接口 + 传统 ML 作为判官。这是 6 月儿科分诊论文的核心思路——LLM 负责把自然语言转结构化特征,传统 ML 模型负责最终判定,能保留医疗场景对「可审计、可回溯」的硬要求。
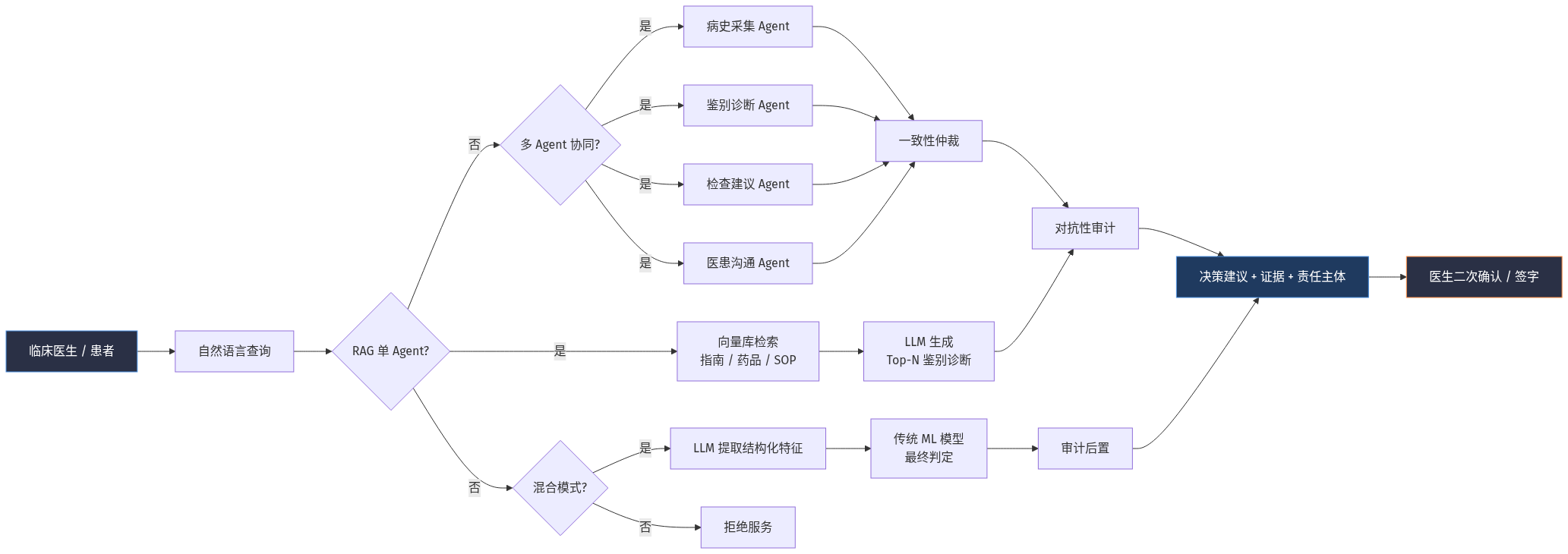
无论哪种路径,2026 年的共识是:LLM 在医疗里是「接口」而非「神谕」——任何把它当作自动开方机器的设想,都会被「幻觉 + 责任主体」两堵墙挡住。
关键点
- 可解释性已是基础门槛:FDA 与多国监管机构对 SaMD(Software as a Medical Device)的要求是「临床医生能理解系统为何给出这个建议」,纯黑盒模型在审批通道上越来越难走通。
- 幻觉问题进入对抗性审计阶段:单纯靠 prompt 抑制幻觉已经不够,6 月新论文普遍引入「后置对抗性审计」作为标准件。
- 垂直病种先行:通用医疗助手尚未跑通,糖尿病管理(GlycemicGPT,GPL-3.0,120 stars)、药物相互作用(SafeMeds)、儿科分诊等单病种 / 单场景项目先跑出来。
- RAG 是默认地基:几乎所有 2026 年的医疗 LLM 项目都建立在 RAG 之上,向量库选型以 Pinecone / Weaviate / Qdrant 为主。
- 合规边界决定上限:HIPAA 在美国的覆盖范围、GDPR 在欧盟的患者数据权利、中国《个人信息保护法》对医疗数据的特殊规定,共同决定了一个 CDSS 系统能跑多大规模。
行业影响:从「能不能」走向「怎么管」
2026 年上半年的标志性变化是:讨论重心已经从「LLM 能不能做临床决策」,转向「LLM 在临床决策流程的哪一环、以何种责任主体介入」。
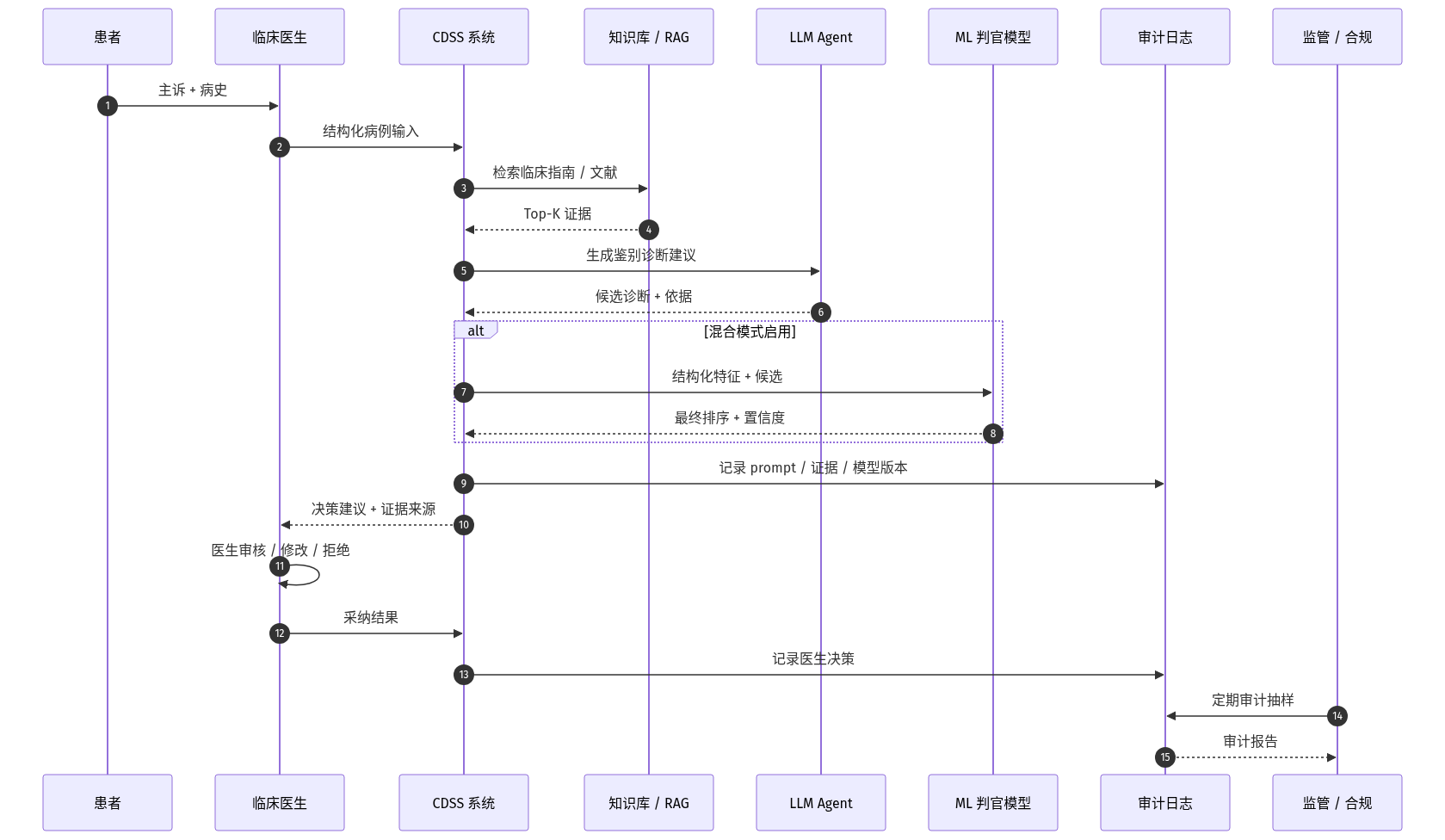
一线医院的实际部署更倾向于「决策建议 + 医生最终签字」的双轨制——LLM 输出「鉴别诊断 Top-N + 依据 + 证据来源」,医生在电子病历系统里勾选「采纳 / 修改 / 拒绝」并留下痕迹。这种模式既绕开了 SaMD 监管中的「全自动诊断」红线,又让 LLM 承担了「缩短医生检索指南时间」的实在价值。
监管侧,FDA 早在 2024 年就把「AI/ML SaMD」列入重点关注清单,2025-2026 年的执法案例显示:对面向消费者的症状自查类 LLM 产品,监管容忍度持续收紧;对面向医务人员的决策辅助类 LLM 产品,则按既有 SaMD 框架分级审批。这意味着 CDSS 厂商的产品定位会显著影响其商业路径。
合规要点(医疗 HIPAA + 中国 PIPL)
- 数据最小化:CDSS 训练 / 推理阶段原则上只使用「为本次决策所必需」的患者数据,避免把全量 EHR 直接灌给 LLM。
- 可审计日志:每一次 LLM 输出建议都必须记录「输入 prompt 摘要 + 检索证据 + 模型版本 + 输出」四要素,便于事后追溯。
- 角色边界:明确「LLM 是辅助、医生是责任主体」,并在 UI 上强制医生对关键决策做二次确认(按钮 / 电子签名)。
- 跨境数据:HIPAA 覆盖下的去标识化数据跨境、欧盟 GDPR 下的充分性认定、中国《数据出境安全评估办法》对医疗数据的额外要求,需在系统架构设计阶段就纳入。
- 模型变更管理:任何基础模型升级、提示词调整、检索库扩容,都应触发一次内部再评估并留档。
结语
LLM 走进诊室已经不是「会不会发生」的问题,而是「在哪个病种、哪种责任结构、哪种合规框架下落地」的问题。2026 年上半年的密集论文与开源项目给出了工程上的多种参考答案,而监管框架则划定了商业上的可行域。对开发者来说,理解临床流程的颗粒度 + 把合规当成产品功能而非成本项,会比单纯刷模型分数更重要。
参考资料:
官方文档
- Medical Heuristic Learning (arXiv:2606.16337) - 2026-06-15 [200]
- Trust but Verify: Mitigating Medical Hallucinations (arXiv:2606.14149) - 2026-06-12 [200]
- Hybrid LLM-ML System for Pediatric Triage (arXiv:2606.19183) - 2026-06-17 [200]
- FDA: Software as a Medical Device (SaMD) - 监管基线
开源项目
- GlycemicGPT - Open-source AI-powered diabetes management - 120 stars, GPL-3.0, 2026-06-24 更新
- multi-agent-clinical-decision-support-system - 多 Agent 可解释对话, 2026-05-16 更新
- safemeds-frontend - drug-to-drug interactions - LLM 药物相互作用查询, 2026-05-14 更新
- Clinical-Decision-Support-System-RAG-Powered-Medical-Chatbot - FastAPI + LangChain + Pinecone 模板, Apache-2.0, 2026-05-05 更新
行业报道
- IEEE Spectrum: Can AI Chatbots Reason Like Doctors? - 2026-05-13 [200]
社区讨论
- HN: GlycemicGPT Show HN (64 points) - 2026-05-15
- HN: Can AI Chatbots Reason Like Doctors? - 2026-05-13
- HN: ReadMyMRI DICOM native preprocessor - 2025-11-04
对比基准
- LMSYS Chatbot Arena Leaderboard - 通用 LLM 医疗能力横向评测基线 [200]
- Hugging Face Papers - 医疗 LLM 论文聚合 [200]
本文由 AI 生成。内容基于公开资料整理,可能存在事实偏差,引用链接请以原始来源为准。