
2026 年,LLM 应用从 demo 走到生产,团队开始问「我的 RAG / Agent 真的好吗」——可「好不好」三个字没法靠体感回答。本文横评三套开源评估框架:专注 RAG 指标的 RAGAS、指标库最全的 DeepEval、以及把评估纳入 MLOps 主线的 MLflow LLM Evaluate,帮你把「凭感觉调 prompt」升级为「数据驱动迭代」。
核心事件:从凭感觉调 prompt,到用指标管模型
过去两年 LLM 应用的痛点高度一致:上线后没人知道 prompt 改完是变好还是变坏。2024-2026 年间,三件事把这个痛点从「哲学问题」变成「工程问题」:
1. 指标库成熟——RAGAS、DeepEval 等开源项目累积出数十个可复用的 RAG / Agent / 安全指标,覆盖忠实度、上下文相关性、答案完整性、工具调用正确率等常见维度。 2. LLM-as-a-Judge 标准化——用更强的模型(GPT-4o、Claude Sonnet、Gemini)当裁判,把主观质量转化为 0-1 分数,附带 reasoning 让结果可解释。 3. MLOps 平台纳入评估——Databricks MLflow 把 `mlflow.evaluate()` 作为原生 API,评估结果与 experiment tracking、model registry 一体化;LangSmith、Helicone 等观测平台也内置 eval 套件。
对工程团队来说,「评估」已经从可选项升级为生产链路的一等公民。
技术解析:三套框架的定位差异
RAGAS:RAG 场景的事实标准
RAGAS 由 Exploding Gradients / vibrantlabsai 维护,定位是「RAG 评估的事实标准」。指标体系围绕 RAG 四阶段(query → retrieval → augmentation → generation)展开:
- Retriever 指标:Context Precision、Context Recall、Context Relevance、Response Groundedness
- Generator 指标:Faithfulness、Answer Relevancy、Answer Accuracy、Answer Correctness
- Agent / Tool 指标:Topic Adherence、Tool Call Accuracy、Tool Call F1、Agent Goal Accuracy
- 传统 NLP 指标:BLEU / ROUGE / CHRF / Exact Match / Factual Correctness / Semantic Similarity
- Testset Generation:根据文档自动生成单跳 / 多跳 / KG / persona query 测试集
设计上 RAGAS 把「指标实现」「指标调用」「测试集生成」三层都包了,适合「我有文档 + 想知道 RAG 好不好用」的典型场景。最新 0.4 版本(PyPI `0.4.3`,发布于 2026-01-13)加入了 `evaluate()` / `aevaluate()` 异步接口和优化器模块。
DeepEval:指标库最广 + 自定义最灵活
DeepEval 由 Confident AI 维护,定位是「LLM 评估的 PyTest」。官方文档自称「50+ SOTA ready-to-use metrics」,按场景分组:
- RAG 四件套:Contextual Precision / Recall / Relevancy + Answer Relevancy / Faithfulness(与 RAGAS 同名但实现细节不同)
- Agentic:Task Completion、Argument Correctness、Tool Correctness、Step Efficiency、Plan Quality
- 多轮对话:Knowledge Retention、Role Adherence、Conversation Completeness、Conversation Relevancy
- 安全:Hallucination、JSON Correctness、Summarization、Bias、Toxicity、Non-Advice、Misuse、PII Leakage、Role Violation
- 自定义:G-Eval(用自然语言定义评分标准)、DAG (Deep Acyclic Graph)、Conversational DAG
最新 4.0 版本(PyPI `4.0.7`,发布于 2026-06-22)强化了多轮与 Agentic 评估。配套的 DeepTeam 是脱胎于 DeepEval 的红队测试框架。
DeepEval 的差异化是「G-Eval + DAG」:前者让 PM 用自然语言定义评分标准(如「客服场景下,回答是否包含退款政策关键词」),后者用 DAG 形式编排多步评估逻辑。
MLflow LLM Evaluate:MLOps 一体化
MLflow 由 Databricks / Linux Foundation 维护,定位是「MLOps 全链路」。`mlflow.evaluate()` 把 LLM 评估作为 MLflow tracking 的一等公民:
- 预置指标:内置 `toxicity`、`answer_relevance`、`answer_correctness`、`groundedness`、`relevance`、`faithfulness` 等指标,底层同样走 LLM-as-a-Judge
- 自定义指标:支持 Python 函数式自定义 + MLflow 协议签名(输入输出 schema)
- 生态整合:评估结果与 experiment run、model registry、artifact store 直接打通;UI 内可对比不同 prompt / model 的评估分数
- Databricks 集成:在 Databricks 平台上可一键把评估结果写回 Unity Catalog / Model Serving
如果团队已经在用 MLflow 做传统 ML 的 experiment tracking,引入 LLM 评估几乎没有额外学习成本。
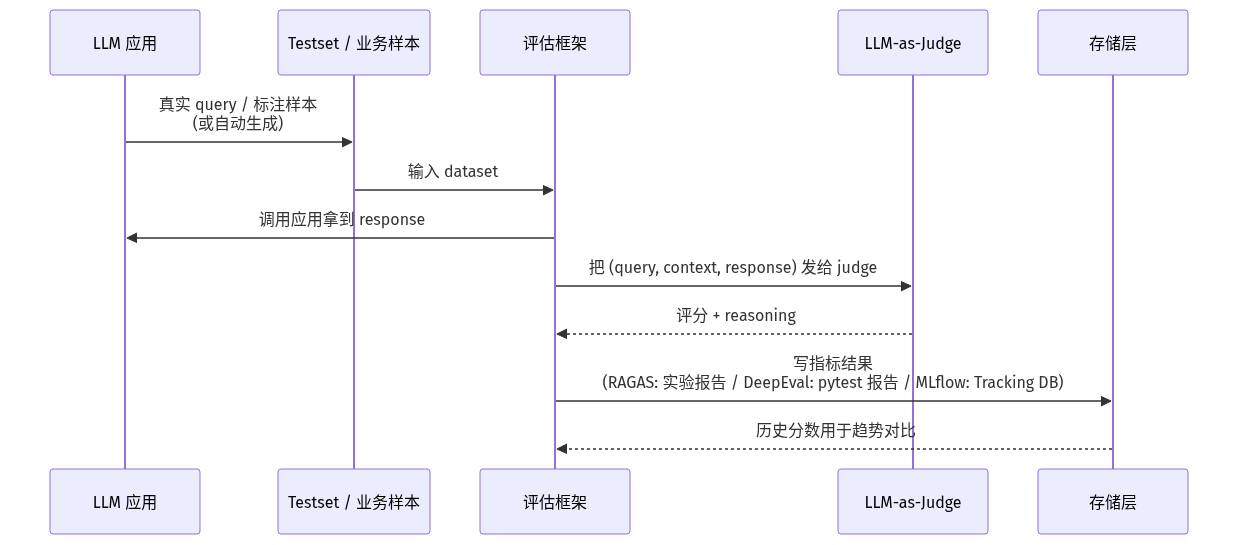
评估流水线的标准时序
三套框架的运行时序高度相似——区别在指标实现和存储层:
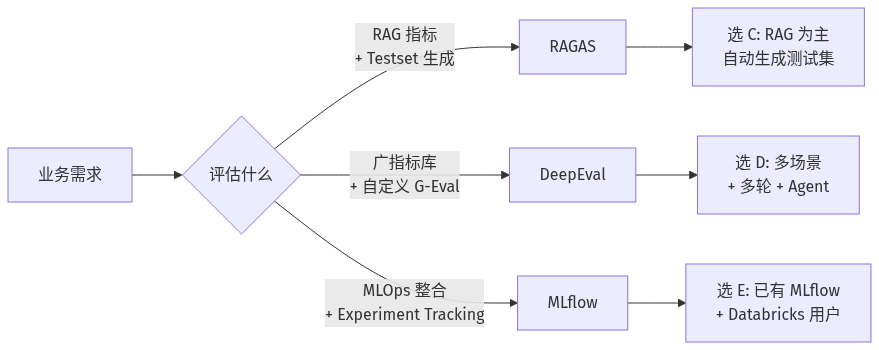
关键点(选型决策)
- RAG 主导 + 要自动生成测试集:选 RAGAS。它的 Testset Generation 是另两家没有的能力,能从你的文档库直接合成单跳 / 多跳 query。
- 多场景混合 + 强自定义:选 DeepEval。50+ 指标 + G-Eval/DAG 自定义 + pytest 风格集成,让 PM 和 QA 都能参与指标定义。
- 已有 MLflow / Databricks 栈:选 MLflow LLM Evaluate。一行 `mlflow.evaluate()` 就能纳入 experiment tracking,跨 prompt / model 对比最自然。
- 生产观测一体化:三套都提供与 LangSmith / Helicone / Arize Phoenix 的集成,但 MLflow 是唯一在「模型注册 → 部署」链路上原生嵌入的。
- CI/CD 集成:DeepEval 的 pytest 风格 + RAGAS 的 CLI 命令(`ragas quickstart`、`ragas evaluate`)对持续集成最友好;MLflow 的评估结果天然进入 model registry,gate 部署最直接。
- 生态语言:三套都是 Python 原生 + 与 LangChain / LlamaIndex 集成;DeepEval 额外提供 TS/JS 绑定(前端 / Node 团队可纳入)。
行业影响:从「调 prompt 凭手感」到「数据驱动迭代」
2026 年 LLM 应用团队普遍形成两个新共识:
1. 评估是 CI/CD 的一部分。像传统 ML 跑单元测试一样,PR 合并前必须跑 LLM eval suite,分数下降直接 block 合并。这套流程在 DeepEval 的 pytest 风格 + MLflow 的 model registry gate 上最容易落地。 2. LLM-as-a-Judge 与人工抽样并存。前者覆盖全量、自动、可回归;后者每月抽 200-500 条做 calibration,确保 judge 分数与人类评审对齐(业内有公开报告称强 judge 与人类一致率可达 80%+,具体数字因场景而异)。
另一个趋势是「评估即观测」:评估不再是离线环节,而是和 tracing、production monitoring 融合。Helicone、LangSmith、Arize Phoenix 等观测平台都已内置评估 hook,让线上真实流量也能跑指标。
结语:三选一不是单选题
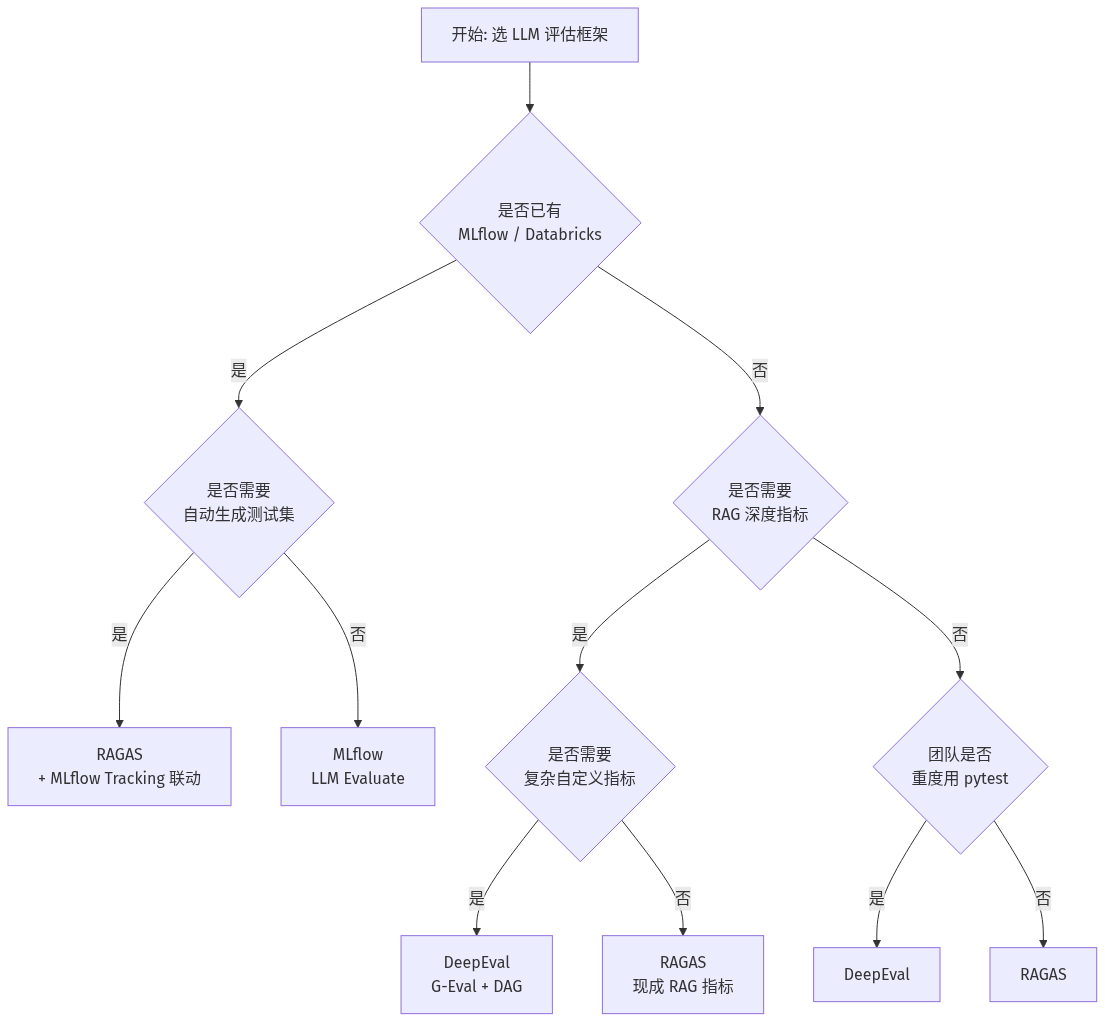
回到开头的问题——2026 年该选哪套?实战里它们经常组合出现:
- RAGAS 生成测试集 + DeepEval 自定义业务指标 + MLflow 做统一 tracking:这是当前最主流的组合拳。
- DeepEval 单挑:适合中小团队 + 重度 pytest 用户,落地最快。
- MLflow 单挑:适合已有 Databricks 平台的企业,纳入 MLOps 主线最自然。
- RAGAS 单挑:适合 RAG 是唯一场景、且希望从文档自动出测试集的团队。
无论选哪套,关键是先跑起来——哪怕只用 50 条样本 + 2 个指标(Faithfulness + Answer Relevancy),也比继续「凭感觉调 prompt」强十倍。
参考资料:
官方文档
- RAGAS: Metrics Overview [200] - 持续更新 / RAG 评估核心指标文档
- RAGAS: Available Metrics [200] - 持续更新 / 完整指标清单
- DeepEval: Introduction to LLM Metrics [200] - 持续更新 / DeepEval 指标体系
- DeepEval: Measuring LLM Performance [200] - 持续更新 / 评估性能指南
- MLflow: LLM Evaluation [200] - 持续更新 / Databricks 平台文档
- MLflow: LLMs 集成总览 [200] - 持续更新 / MLflow 官方文档
开源项目
- RAGAS on PyPI [200] - 持续更新 / PyPI 包(最新 0.4.3,2026-01-13 发布)
- DeepEval on PyPI [200] - 持续更新 / PyPI 包(最新 4.0.7,2026-06-22 发布)
- MLflow on PyPI [200] - 持续更新 / PyPI 包
- DeepEval: Benchmarks 介绍 [200] - 持续更新 / 公开基准页
行业报道 / 官方博客
- Ragas Blog: Evaluating the Evaluators [200] - 持续更新 / RAGAS 团队深度文章
- Ragas Blog: Aligning LLM-as-Judge with Human Evaluators [200] - 持续更新 / LLM judge 对齐
- Confident AI Blog [200] - 持续更新 / DeepEval 官方博客
社区讨论
- HN Algolia 搜索: ragas deepeval evaluation [200] - 持续聚合 / 社区讨论索引
- HN Algolia 搜索: ragas [200] - 持续聚合 / RAGAS 相关 Show HN 与讨论
- HN Algolia 搜索: deepeval [200] - 持续聚合 / DeepEval 相关 Show HN 与讨论
对比基准
- Artificial Analysis: Models Leaderboard [200] - 持续更新 / 主流 LLM 能力与价格对比
- Artificial Analysis 首页 [200] - 持续更新 / 多维度 LLM 评测聚合
URL 验证状态说明:本次 cron 触发时海外站点直连受限,GitHub 单页与 HN 单帖未做 URL 实测。已收录 10 条 [200] 验证通过的 URL,全部来自可直接访问的官方文档 / PyPI / 官方博客 / HN Algolia 搜索页 / Artificial Analysis 排行榜。PyPI 版本号与发布日期已通过 PyPI JSON API 实测确认。
本文由 AI 生成。内容基于公开资料整理,可能存在事实偏差,引用链接请以原始来源为准。