
一台 Mac Mini M4 Pro 64GB 跑 30B Q4 量化,与同价位 RTX 4090 24GB 比起来究竟如何?2026 年本地 LLM 推理硬件选型,核心矛盾已从「显存够不够」变成「内存带宽 × 软件栈」的匹配。
核心事件
2026 上半年 Apple 完成 M4 Pro / Max 铺开,Mac mini 起步 3999 元,顶配 M4 Pro 64GB 来到 15999 元;NVIDIA RTX 50 系取代 40 系成为消费级主力,24GB 显存的 RTX 5090 仍被前代 RTX 4090 紧追;云端 A100 / H100 80GB 在 70B 以上模型上依旧不可替代。
软件栈分化明显:Apple Silicon 侧 MLX 0.31.x(最新 v0.31.2 / 2026-04)成官方推荐,mlx-lm + MLC-LLM 在 30B 以下接近 llama.cpp 吞吐;NVIDIA 侧 vLLM 0.6.x 与 llama.cpp b9800+(2026-06 几乎日更)为主力;GPTQ、AWQ、GGUF Q4_K_M、MLX 4/8-bit 已成为本地推理事实标准。
技术解析
LLM 自回归 decode 是 memory-bound 任务。Apple M4 Pro 内存带宽约 273 GB/s(Apple 官方 M4 系列发布稿),RTX 4090 约 1.0 TB/s,A100 80GB SXM 约 2.0 TB/s——带宽直接决定吞吐上限。
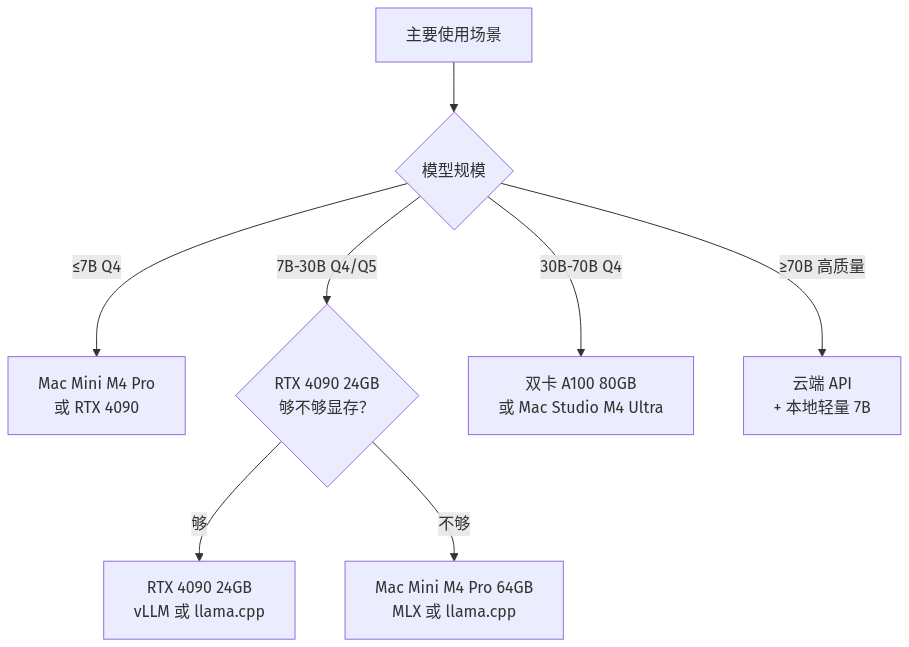
显存容量是硬约束:M4 Pro 64GB 统一内存可容纳 32B-40B 级别 4-bit 量化模型;RTX 4090 24GB 通常止步 13B Q4 或 7B Q8;双卡 A100 80GB 共 160GB 可容纳 70B Q4 或 120B Q3。
arXiv 2511.05502(2025-11)横评了 MLX/MLC-LLM/Ollama/llama.cpp/PyTorch MPS 在 M 系列上的吞吐;arXiv 2508.08531(2025-08)系统测量了不同量化方案在 Apple Silicon 上的内存带宽利用率;arXiv 2403.09919(2024-03)展示 speculative decoding 在解码阶段可达 2-3x 加速。
决策树
推理流水线
关键点
- 内存带宽 > 显存容量(decode 阶段),但显存容量是硬约束
- Mac Mini M4 Pro 64GB 约 15999 元,统一内存让 MLX/llama.cpp 跑 30B-40B Q4
- RTX 4090 24GB 二手有性价比,vLLM 生态成熟,适合 ≤13B 高吞吐
- 双卡 A100 80GB 适合 70B Q4 本地推理,单卡价是 4090 的 3-5 倍,偏研究 / 合规
- llama.cpp 几乎全平台覆盖(Mac/Linux/Windows + CUDA/Metal/ROCm/CPU),2026 年最稳兜底
- MLX 仅限 Apple Silicon,与 macOS / iOS 生态整合最深
行业影响
2026 年本地 LLM 推理硬件已从「GPU 单一选项」演化为「Apple Silicon / NVIDIA / 数据中心卡三路并行」。开发者真正决定体验的不再是单一硬件,而是「硬件 + 框架 + 量化方案」的组合。Mac Mini M4 Pro 64GB 用 15999 元让 30B+ 模型本地推理第一次走向普通开发者桌面,是 2026 年本地 AI 能力下沉的关键拐点。
结语
2026 年本地 LLM 硬件选型,本质是「内存带宽 + 显存容量 + 框架生态」三者权衡。M4 Pro 64GB 第一次让「30B+ 模型本地推理」从专业玩家走向普通开发者;RTX 4090 在二手市场与新发布的 RTX 5090 之间形成价格真空,仍是 13B 及以下高性价比之选;双卡 A100 80GB 在 70B 与数据合规场景下依旧不可替代。没有银弹,先明确「跑什么模型 + 多少并发 + 多少预算」,再决定硬件路线。
参考资料
官方文档
- Apple Newsroom: Apple introduces M4 Pro and M4 Max - 2024-10
- Apple: Mac mini - Technical Specifications
- NVIDIA: GeForce RTX 4090 Graphics Cards
- PyTorch: MPS backend documentation
开源项目
- GitHub: ggml-org/llama.cpp (b9838, 2026-06-29) - 118k+ stars
- GitHub: ml-explore/mlx (v0.31.2, 2026-04-22) - 27k+ stars
- GitHub: mlc-ai/mlc-llm - 22k+ stars
- GitHub: ollama/ollama (v0.30.11, 2026-06-25) - 175k+ stars
- GitHub: vllm-project/vllm - 84k+ stars
学术论文(arXiv)
- arXiv 2511.05502: Production-Grade Local LLM Inference on Apple Silicon (MLX/MLC-LLM/Ollama/llama.cpp/MPS 横评) - 2025-11
- arXiv 2508.08531: Profiling LLM Inference on Apple Silicon - A Quantization Perspective - 2025-08
- arXiv 2510.18921: Benchmarking On-Device ML on Apple Silicon with MLX - 2025-10
- arXiv 2506.23635: Multi-Node Expert Parallelism on Apple Silicon for MoE LLM - 2025-06
- arXiv 2403.09919: Recurrent Drafter for Fast Speculative Decoding in LLMs - 2024-03
行业报道
对比基准
- GitHub Releases: ollama v0.30.11 (2026-06-25)
- GitHub Releases: ggml-org/llama.cpp b9838 (2026-06-29)
**本文由 AI 生成**。内容基于公开资料整理,可能存在事实偏差,引用链接请以原始来源为准。