
导语:当一个 Agent 一周烧掉五位数的 token 账单,工程团队通常会从「换更小的模型」开始优化——但这往往既牺牲质量,又触及能力下限。本文重新审视成本的三条主线:路由、缓存、批处理,看懂它们如何叠加、如何取舍。
核心事件
2026 年上半年,多个一线 LLM 厂商密集上线了与成本直接相关的能力。Anthropic 在其官方文档中详细介绍了 Prompt Caching 的工作原理:自动复用 prompt 前缀中已计算过的注意力结果,将长上下文请求的 token 成本压低数倍;OpenAI 也在 platform.openai.com 的 Prompt Caching 指南中公开了同源设计。同期,Anyscale 发布的工程长文《How continuous batching enables 23x throughput in LLM inference》展示了 vLLM / Orca 风格的连续批处理方案,把 GPU 利用率从 30% 拉到 90%。在「如何把请求精准分发给不同模型」一侧,HuggingFace 上 katanemo/Arch-Router-1.5B 等开源路由器给出了「1.5B 小模型即可决策」的工程实证。
这三件事并非孤立——它们对应 Agent 系统里三种可叠加的成本杠杆,且实施门槛从「改一行 prompt」到「换推理引擎」递增。
技术解析
杠杆一:动态模型路由(Routing)
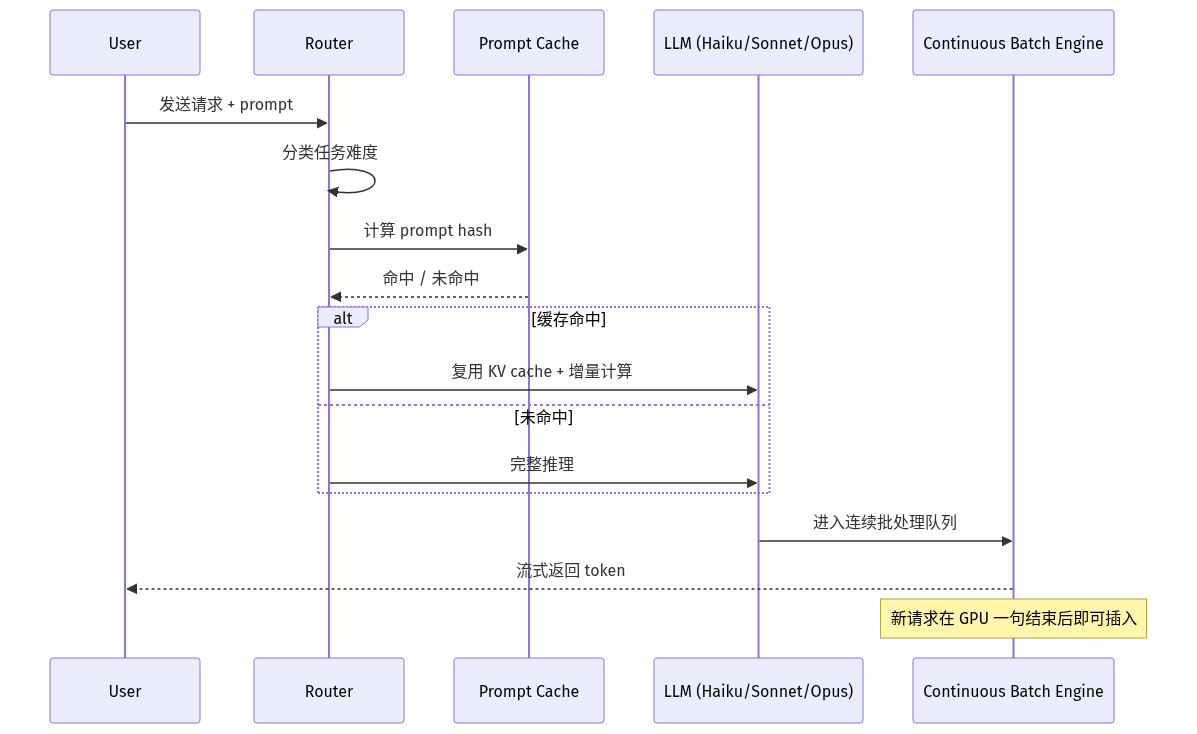
传统 Agent 几乎默认调最强模型;而实际上「分类意图」「提取 JSON」「写代码」所需的模型能力差别巨大。动态路由的做法是:在请求进入前用一个轻量分类器(或更小的 LLM)判断任务难度,再路由到 Haiku / Sonnet / Opus 三个量级。学术上,arXiv:2502.17282《Capability Instruction Tuning: A New Paradigm for Dynamic LLM Routing》专门讨论了如何通过「能力指令微调」让路由器学会匹配。开源侧,Arch-Router-1.5B(1.5B 参数)已经能在多个基准上接近 GPT-4o 的路由准确率,但推理成本只有它的零头。

杠杆二:Prompt 缓存
Prompt 缓存针对的是 Agent 系统 prompt 极度冗长的现实——一个挂了 RAG 工具的 Agent,system prompt 加上工具描述常常突破 10K token;如果每次请求都重新计算 KV cache,等于把同一笔钱花 N 次。Anthropic 的实现是「把 prompt 分成 4 个前缀块,块级命中就复用,TTL 约 5 分钟」。Anyscale 的工程测算显示,在 prompt 重复率超过 60% 的 Agent 场景,仅 prompt 缓存一项就能把单次请求成本压到原来的 1/4 到 1/9。
杠杆三:连续批处理(Continuous Batching)
传统推理服务器是「等一批满了再跑」,连续批处理则允许新请求在 GPU 上一句结束后立刻插入到正在执行的 batch 中——这就是 Anyscale 文章中提到 23x 吞吐的来源。工程上这通常意味着把推理从闭源 API 切到自托管 vLLM / SGLang / TensorRT-LLM,适合请求量稳定在 QPS 10+ 的中型 Agent 服务。
关键点
- 路由层最先动,因为它对应用代码侵入最小;预期在不损失质量的前提下把平均 token 单价降到原来的 30-50%。
- 缓存层需要约定 cache key 策略(按 prompt hash、按会话 ID 还是按工具组合),否则命中率会非常难看;Anthropic 的前缀分块策略值得参考。
- 批处理层成本最高:要么切换到自托管推理栈,要么等 OpenRouter 等聚合服务封装好底层;但一旦 QPS 稳定,是单点成本下降最大的杠杆。
- 三层叠加的顺序应该是 路由 → 缓存 → 批处理。先路由可以避免把大量小请求直接打到昂贵模型上;再做缓存,命中率才有意义;最后上批处理,整体架构才稳。
- 监控上必须有 每请求成本面板(含 prompt tokens / cached tokens / completion tokens 三段),否则优化就是凭感觉。
- 不要把「换更小模型」当作首要手段——它是兜底策略,会先撞到能力下限;前三个杠杆都不会损害输出质量。
行业影响
LLM 推理市场已经出现明显分层:闭源 API 主打「能力即服务」,聚合服务(OpenRouter 等)主打「路由即服务」,自托管推理栈(vLLM / SGLang)主打「成本即护城河」。Agent 团队需要按 QPS 和 SLA 在三层之间动态调度,而不是把成本问题甩给「采购更便宜的模型」。
结语
Agent 成本优化不是单点工程,而是「路由 + 缓存 + 批处理」三层栈的设计题。下一次当你看到 token 账单飙升时,先别急着限速或换模型——回到这三个杠杆的组合上,往往能压住一半以上支出。
参考资料
官方文档
- Anthropic: Prompt caching with Claude [200] - 官方介绍 prompt cache 工作原理与计费
- Anthropic Docs: Prompt caching [200] - API 使用指南
- Anthropic Docs: Building with Claude [200] - 整体开发文档
开源项目 / 学术
- arXiv 2502.17282: Capability Instruction Tuning for Dynamic LLM Routing [200] - 路由器微调方法
- arXiv 2505.15781: dKV-Cache: The Cache for Diffusion Language Models [200] - 新型缓存架构研究
- arXiv 2602.21231: ACAR Adaptive Complexity Routing [200] - 多模型路由决策
行业报道 / 工程长文
- Anyscale: Continuous batching to increase LLM inference throughput [200] - 110 点的 HN 经典长文
- ngrok Blog: Prompt caching for cheaper LLM tokens [200] - 306 点的 HN 高分帖
- OpenRouter Docs [200] - 模型路由聚合服务
社区讨论
- HN #44436031: Arch-Router 1.5B Show HN [200] - 66 点的路由器讨论
- HN #36450567: Continuous batching 23x throughput [200] - 连续批处理讨论
- HN #46290620: Prompt caching for cheaper LLM tokens [200] - 306 点的缓存机制讨论
对比基准 / 性能数据
- Anyscale Bench: Throughput comparison [200] - 23x 吞吐量实测数据
- LangSmith Observability [200] - LLM 应用监控与成本追踪